Paper Reading/Review
[리뷰] SMILEtrack: SiMIlarity LEarning for Multiple Object Tracking
- -
728x90
반응형
이번에는 2022년에 발표된 논문인 SMILEtrack: SiMIlarity LEarning for Multiple Object Tracking를 읽고, 리뷰해보고자 합니다.
Index
1. Background
1.1. Seperate Detection and Embedding
1.2. ByteTrack
2. Abstract
3. Introduction
3.1. Previous Method
3.2. Proposed Method
4. Related Work
5. Method
5.1. Architecture Overview
5.2. Similarity Learning Module for Re-ID
5.3. The Image Slicing Attention Block
5.4. Image Slicing
5.5. The Q-K-V attention block
5.6. Similarity Matching Cascade for Target Tracking
6. Experiment
7. Conclusion
1. Background
1.1. Seperate Detection and Embedding
Seperate Detection and Embedding
1. 개념 detector와 re-identification model로 이루어진 object tracker 2. 작동 원리 detector를 이용하여 object를 찾은 후, re-ID moddel에서 detected bounding box의 feature에 대한 embedding을 생성 detection에 대해 기존의 tra
alstn59v.tistory.com
1.2. ByteTrack
[리뷰] ByteTrack: Multi-Object Tracking by Associating Every Detection Box
이번에는 최근 MOT에서 SOTA를 달성한 ECCV 2022에 게재된 논문인 ByteTrack: Multi-Object Tracking by Associating Every Detection Box를 읽고, 리뷰해보고자 합니다. Index 1. Background 1.1. Kalman Filter 1.2. Hungarian Algorithm 1.
alstn59v.tistory.com
2. Abstract
- TBD는 MOT에서 많이 사용되는 방식으로, detection과 association의 2 stage로 구성
- object의 appearance feature를 추출하기 위해 siamese network에서 영감을 받은 similarity learning module과 feature와 motion을 결합하는 방법 제안
- siamese network는 입력받은 두 image를 벡터화 시킨 후, 두 벡터의 similarity를 출력하는 네트워크
- association을 위해 feature와 motion의 모델링 강화하며, similarity matching cascade 방식 제안
3. Introduction
3.1. Previous Method
- 높은 성능을 달성한 model들은 대부분 TBD 방식을 이용
- object가 애매모호하거나, occlusion, 복잡한 장면에서 성능 하락
- detection과 re-ID에 사용되는 feature를 공유하는 joint detection and embedding 방식과 그렇지 않은 seperate detection and embedding 방식이 있음
- detection과 re-ID는 목적이 상반되기 때문에 필요한 feature도 달라야하므로, 서로간의 성능을 제한시키는 JDE 방식은 문제가 있다고 주장
- 최근 attention에 기반한 transformer 구조는 detection과 association을 결합하여, 단일 model로 tracking 수행
3.2. Proposed Method
- JDE 방식의 문제점을 해결하기 위해 SDE 방식을 선택
- 대부분의 feature descriptor는 다른 object와의 구별을 명확하게 하지못한다고 주장
- 문제의 해결을 위해 detector와, ViT에서 영감을 받은 image slicing attention block을 사용하는 similarity learning module을 결합한 model 제안
- 각 frame의 object를 matching하기 위해 similarity matching cascade 방식 제안
- 즉, detector를 이용해 object를 찾아낸 후, bounding box를 similarity matching cascade에 의해 생성된 track과 association 수행
4. Related Work
- tracking by detection
- detection Method
- R-CNN, YOLO, CornerNet, CenterNet, YOLOX, …, etc
- data association Method
- SORT, DeepSORT, FairMOT, …, etc
- detection Method
- tracking by attention
- Trackformer, TransTrack, MOTR, …, etc
5. Method
5.1. Architecture Overview
- detection과 tracking의 두 부분으로 나뉨

5.2. Similarity Learning Module for Re-ID
- robust한 tracking을 위해 appearance 정보는 필수적이지만, 다른 object와 appearance feature를 명확하게 구분할 수 없음
- 차별적인 appearance feature를 추출하기 위해 siamese network와 유사한 similarity learning module 제안
- appearance feature의 학습을 위해 cosine similarity distance를 이용
- 동일 object의 similarity score는 가능한 한 높아야하며, 그렇지 않은 경우에는 0에 가까워야 함

5.3. The Image Slicing Attention Block
- 신뢰할 수 있는 appearance feature를 생성하기 위해서는 성능 좋은 feature extractor가 필수적임
- transforemr는 feature enhancement에 뛰어난 성능을 가졌지만, 계산 cost가 높음
- ViT에서 영감을 받아 image slicing과 feature extract를 위한 attention을 적용하는 방법 제안

5.4. Image Slicing
- Q-K-V attention block의 input으로 사용하기 위해, detector를 이용하여 bounding box \( B \) 생성
- 각 \( B \)의 크기는 모두 다르기 때문에 \( B \in R^{w \times h} \)로 resize
- MOT dataset을 train할 때, \( w=80 \), \( h=224 \) 이용
- \( B \)의 feature map을 생성하기 위해 Resnet-18을 이용하고, \( S_{i} \in R^{n \times s \times t} \)로 slicing함
- \( n=4 \)은 slice된 것의 수, \( s \times t \)는 slice된 piece의 크기
- \( S_{i} = S_{i}+E_{p} \)
- \( i=A,B,C,D \), \( E_{p}=1,2,3,4 \), \( E_{p} \)는 1D position embedding
5.5. The Q-K-V attention block
- transformer는 sequence의 장기적인 의존성을 처리하기에 좋으며, attention block이 중요
- attention 함수는 아래와 같이 계산
- \( Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V \)
- \( d_{k} \)는 key vector의 차원
- \( Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V \)
- attention block의 Q, K, V 값을 생성하기 위해 각 slice에 대해 FC layer 적용하며, output으로 가 나옴
- \( S_{i}=SA(Q_{S_{E_{p}}}, K_{S_{E_{p}}}, V_{S_{E_{p}}})+\sum^{4}_{k \neq E_{p}}{CA(Q_{S_{E_{p}}}, K_{S_{k}}, V_{S_{k}})} \)
- \( i=A,B,C,D \), \( E_{p}=1,2,3,4 \), \( SA \)는 self-attention, \( CA \)는 cross-attention
- feature \( S_{i} \)를 가진 후, input image의 feature를 유지하기 위해 concatenate 매커니즘을 사용하여 융합
- \( S_{i}=SA(Q_{S_{E_{p}}}, K_{S_{E_{p}}}, V_{S_{E_{p}}})+\sum^{4}_{k \neq E_{p}}{CA(Q_{S_{E_{p}}}, K_{S_{k}}, V_{S_{k}})} \)
- attention 함수는 아래와 같이 계산
5.6. Similarity Matching Cascade for Target Tracking
- ByteTrack의 algorithm을 따름
- score가 높은 detection들, 즉 \( D_{high} \)에 대해 먼저 association 수행
- assiciation되지 못한 detection들, 즉 \( D_{low} \)에 대해 수행하는 과정을 이용
- 그러나, object들이 가까워질 때 association하는 과정에서 IoU diastance만 사용하므로 문제가 발생
- 문제의 해결을 위해 ByteTrack의 장점과 SLM을 통합

- 1st association
- motion matrix \( M_{m} \), \( D_{high} \)와 \( TL \)의 appearance similarity matrix \( M_{a} \)를 계산
- \( M_{m} \)의 경우, \( D_{high} \)와 \( TL \)의 IoU distance
- \( M_{a} \)는 SLM을 이용하여 계산
- 즉, feature similarity
- 아래의 수식을 이용하여 gate function으로 이용할 cost matrix \( C_{high} \)를 만들고, hungarian algorithm에 이를 이용하여 matching 수행
- \( C_{high} = M_{m}(i,j)-(1-M_{a}(i,j)) \)
- \( i \)는 i번째 tracklet, \( j \)는 j번째 detection
- \( C_{high} = M_{m}(i,j)-(1-M_{a}(i,j)) \)
- motion matrix \( M_{m} \), \( D_{high} \)와 \( TL \)의 appearance similarity matrix \( M_{a} \)를 계산
- 2nd association
- 1st assiciation과 마찬가지로 \( D_{low} \)와 \( TL_{remain} \)에 대해 \( M_{m} \)을 계산
- \( M_{a} \)의 경우, low score detection과 track 사이의 similarity를 학습하기 위해 multi-template-SLM 이용
- low score detection \( d \)을 다루기 위해 마지막 frame의 feature를 similarity 계산에 직접적으로 이용하면 신뢰할수 없는 score가 생성되고, 이를 해결하기 위해 track의 다른 frame들에 있는 feature를 memory bank \( F \)에 저장하여 이용
- \( M_{a}(i,j)=max\{SLM(f_{i}, d_{j}) | \text{ for all } f_{i} \in F_{i}\} \)
- \( M_{m} \)과 \( M_{a} \)를 이용하여 1st association에서의 \( C_{high} \)처럼 cost matrix \( C_{low} \)를 만들고, hungarian algorithm에 이를 이용하여 matching 수행
- low score detection \( d \)을 다루기 위해 마지막 frame의 feature를 similarity 계산에 직접적으로 이용하면 신뢰할수 없는 score가 생성되고, 이를 해결하기 위해 track의 다른 frame들에 있는 feature를 memory bank \( F \)에 저장하여 이용
- association 과정이 끝나고, \( D_{low} \)에서 matching되지 않은 detection과 \( TL_{Remain} \)에서 matching되지 않은 track은 \( D_{RRemain} \)과 \( TL_{RRemain} \)에 저장
- 새로운 track을 초기화 하기 위한 threshold값 \( H \)를 정하여, \( H \)보다 높은 점수를 가진 \( D_{Remain} \)의 detection은 새로운 track의 초기화에 이용
- \( TL_{RRemain} \)의 matching되지 않은 track은 lost object list \( LL \)에 저장하고, \( D_{RRemain} \)은 background로 간주하며, \( LL \)에 track이 30 frame 이상 존재하는 경우에 \( LL \)에서 track 삭제
6. Experiment
- MOT dataset에서의 성능 비교

- attention의 feature dimension 수에 따른 성능 변화

- gate function과 multi-template-SLM의 사용 여부에 따른 성능 변화


- association 과정의 각 stage에서 similarity matrix의 종류에 따른 성능 변화
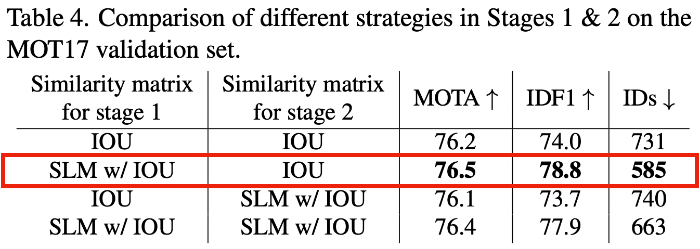
7. Conclusion
- siamese network와 같은 구조의 SMILEtrack 제안
- 각 frame에서 detected object를 assocation하기 위한 SMC 개발
- SDE 방법이기 때문에, JDE 방법보다 수행 속도가 느린 단점 존재
논문 링크
https://arxiv.org/abs/2211.08824v2
https://github.com/WWangYuHsiang/SMILEtrack
참고 링크
https://blog.mathpresso.com/샴-네트워크를-이용한-이미지-검색기능-만들기-f2af4f9e312a
728x90
반응형
'Paper Reading > Review' 카테고리의 다른 글
Contents
소중한 공감 감사합니다