Paper Reading/Review
[리뷰] StrongSORT: Make DeepSORT Great Again
- -
728x90
반응형
이번에는 IEEE 2023에 게재된 논문인 StrongSORT: Make DeepSORT Great Again를 읽고, 리뷰해보고자 합니다.
Index
1. Background
1.1. Mahalanobis Distance
1.2. Exponential Moving Average
1.3. High Order Tracking Accuracy
2. Abstract
3. Introduction
4. Related Work
5. Method
5.1. Review of DeepSORT
5.2. Stronger DeepSORT
5.3. Appearance-Free Link model
5.4. Gaussian-Smoothed Interpolation
6. Experiment
7. Conclusion
1. Background
1.1. Mahalanobis Distance
Mahalanobis Distance
1. 개념 확률 분포 속의 거리 아래 그림에서 점 A가 평균과 표준편차로 표현될 때, 표준편차의 크기를 이용해 거리 산정 즉, 평균과의 거리가 표준편차의 몇 배인지 나타냄 2. 계산 방법 \( D^{2}=(x-m
alstn59v.tistory.com
1.2. Exponential Moving Average
Exponential Moving Average
1. 개념 과거의 모든 기간을 계산대상으로 하며, 최근의 데이터에 더 높은 가중치를 두는 일종의 가중이동평균법 2. 계산 방법 \( x_{k}=\alpha p_{k}+(1-\alpha)x_{k-1} \text{ where } \alpha=\frac{2}{N+1} \) \( \alpha
alstn59v.tistory.com
1.3. High Order Tracking Accuracy
Tracking Evaluation Metrics
MT; Mostly Tracked trajectories↑ : 궤적의 수명(한 object의 궤적에 대해 동일한 ID를 가진 정도 혹은 시간)이 최소 80% 이상인 궤적의 수 PT; Partially Tracked trajectories : 궤적의 수명이 20~80% 인 궤적의 수 ML; Mo
alstn59v.tistory.com
2. Abstract
- 기존의 MOT는 tracking by detection과 joint detection association의 방법으로 분류 가능하며, 후자가 더 관심을 끌지만, 여전히 전자가 정확도가 높음
- DeepSORT를 detection, embedding, association 등 다양한 측면에서 업그레이드 하였으며, tracking 결과를 개선하기 위해 아래의 요소를 제시
- tracklet을 trajectory로 연결하는데 이용하는 appearance-free link model 제안
- 누락된 detection을 보완하는 gaussian-smoothed interpolation 제안
- AFLink와 GSI는 무시 가능한 계산 비용으로 다양한 tracker에 삽입 가능
3. Introduction
- 최근 joint tracker가 TBD대비 계산 cost가 저렴하고 성능이 잘 나와 주목받고 있음
- 서로 다른 요소사이의 경쟁 문제와 이 요소들을 joint하게 훈련시킬 data가 제한되어 있는 문제가 있으며, 이 문제들이 tracking accuracy의 상한선을 낮춘다고 주장
- 따라서 classic seperate tracker인 DeepSORT에 다양한 advanced components를 장착하고, MOT dataset에서 SOTA 달성
- tracking 결과를 개선하기 위해 두 가지 요소 제시
- 두 개의 input tracklet이 동일한 ID에 속하는지 여부를 예측하기 위해 시공간 정보만을 활용하는 appearance-free link model 제안
- global information을 더 잘 활용하기 위해 몇 가지 방법들은 global link model을 제안하는데, 이 방법은 tracking 성능을 크게 향상시켰지만 computation-intensive하고, appearance embedding에 의존하기 때문
- gaussian process regression기반의 gaussian smoothed interpolation 제안
- linear interpolation은 누락된 탐지를 보완하는 데 널리 사용하지만, motion information을 무시하여 accuracy를 제한하기 때문
4. Related Work
- tracker의 종류
- seperate tracker, joint tracker
- global link in MOT
- temporal-spatial or appearance 정보를 사용하여 tracklet을 생성한 것을 오프라인 방식으로 풍부한 global information을 탐색하여 연결
- interpolation in MOT
- linear interpolation은 누락된 detection이 복원된 trajectory의 빈 부분을 채우기 위해 주로 사용되지만, motion information을 무시하여 bounding box의 accuracy를 제한
5. Method
5.1. Review of DeepSORT
- DeepSORT는 appearance branch와 motion branch로 요약할 수 있음
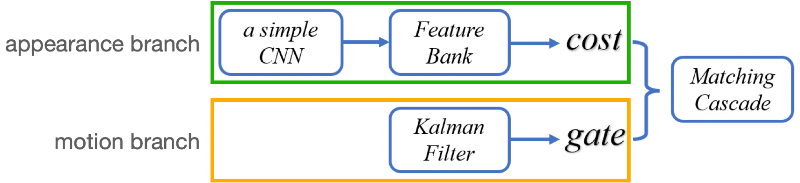
- appearance branch
- 각 frame에서 detection이 주어지면 MARS dataset으로 pre-train된 simple CNN인 deep appearance descriptor가 detection의 appearance feature를 추출
- 각 tracklet에 대해 마지막 100 frame의 feature를 저장하기 위해 feature bank mechanism을 사용
- 새로운 detection(\( j \)-th)이 발생하면, \( i \)-th tracklet의 feature bank \( R_{i} \)와 \( j \)-th detection의 feature인 \( f_{j} \)사이의 최소 코사인 거리를 아래와 같이 계산하며, association 과정 동안 matching cost로 사용
- \( d(i,j)=min\left\{1-f_{j}^{T}f_{k}^{(i)}|f_{k}^{(i)}\in R_{i}\right\} \)
- motion branch
- kalman filter를 이용하여 현재 frame에서 tracklet의 위치를 예측
- mahalanobis distance를 이용하여 tracklets와 detections의 spatio-temporal dissimilarity인 motion distance를 측정
- motion distance를 타당하지 않은 association을 필터링하기 위한 gate로 사용
- 할당 문제를 global problem으로 보지 않고, subproblem의 series로 보고 cascade algorithm을 이용하며, 자주 보이는 object에 높은 매칭 우선 순위를 부여하는 것이 핵심
- subproblem은 헝가리 알고리즘을 사용하여 할당
5.2. Stronger DeepSORT
- StrongSORT도 마찬가지로 appearance branch와 motion branch로 요약할 수 있음

- appearance branch
- DeepSORT의 simple CNN을 ResNeSt50을 backbone으로 하고, DukeMTMC-reID dataset으로 pre-train한 appearance feature extractor인 BoT로 대체
- feature bank를 지수 이동 평균 방식을 이용한 feature update 전략으로 대체하여 matching quality를 향상시키고 소비 시간을 줄였으며, \( i \)-th tracklet frame에 대한 appearance state \( e_{i}^{t} \)를 아래와 같이 계산
- \( e_{i}^{t}=\alpha e_{i}^{t-1}+(1-\alpha)f_{i}^{t} \)
- \( \alpha \) is momentum term, \( f_{i}^{t} \)is appearance embedding of current matched detection
- \( e_{i}^{t}=\alpha e_{i}^{t-1}+(1-\alpha)f_{i}^{t} \)
- motion branch
- camera motion compensation을 위해 enhanced correlation coefficient maximization을 채택
- vanilla kalman filter는 low-quality detections에 취약하고, detection noise의 scale에 대한 정보를 무시하기 때문에, noise 공분산 \( \tilde{R}_{k} \)를 적응적으로 계산하는 GIAOTracker의 NSA kalman algorithm로 대체하며, \( \tilde{R}_{k} \)은 아래와 같이 계산
- \( \tilde{R}_{k}=(1-c_{k})R_{k} \)
- \( R_{k} \) is preset constant measurement noise covariance, \( c_{k} \) is the detection confidence score at state \( k \)
- \( \tilde{R}_{k}=(1-c_{k})R_{k} \)
- matching시 appearance feature distance만 사용하는 대신, appearance와 motion 정보를 이용하여 할당 문제 해결
- cost matrix \( C \)는 아래와 같이 계산
- \( C=\lambda A_{a}+(1-\lambda)A_{m} \)
- \( A_{a} \) is appearance cost, \( A_{m} \) is motion cost
- \( C=\lambda A_{a}+(1-\lambda)A_{m} \)
- tracker의 성능이 강력해질 수록 confusing한 association에 대해 더 robust해져서 성능을 제한한다는 점을 발견하여, matching cascade를 vanilla global linear assignment로 대체
5.3. Appearance-Free Link model
- 아래의 문제를 극복하기 위해, 두 tracklet의 연결을 예측하는 appearance-free link model 제시
- tracklet에 대한 global link는 정확한 association을 추구하기 위해 사용되지만, fine-tune 하기 위해 계산 비용이 높은 요소와 수많은 hyperparameter에 의존
- appearance feature에 과하게 의존하면 noise에 취약해짐
- 최근의 30 frames들에서 \( k \)-th frame \( f_{k} \)와 positions \( (x_{k},y_{k}) \)로 구성된 tracklet인 \( T_{*}=\left\{f_{k},x_{k},y_{k}\right\}_{k=1}^{N} \)2개 (\( T_{i} \), \( T_{j} \))를 input으로 가짐
- 30 frames 보다 짧을 경우, zero padding 사용
- temporal module은 \( 7 \times 1 \) kernel로, temporal 차원을 따라 convolution 연산을 수행하여 feature를 추출
- fusion module은 \( 1 \times 3 \) convolution 연산을 수행하여, 서로 다른 feature 차원의 정보(\( f \), \( x \), \( y \))를 통합
- 마지막에 association을 위한 confidence score를 예측할 때 MLP가 사용됨
- association 동안 spatio-temporal 제약을 이용해 합리적이지 않은 tracklet을 걸러내고, 예측된 score를 hungarian algorithm을 이용하여 linear assignment 수행
5.4. Gaussian-Smoothed Interpolation
- linear interpolation은 motion information을 무시하여 bounding box의 accuracy를 제한되는 문제
- single object tracker, kalman filter, ECC와 같은 방법이 제시되었음
- 본 논문은 nonlinear motion을 모델링하기 위해 gaussian process regression을 이용하는 lightweight interpolation algorithm 제시
- \( i \)-th trajectory에 대한 GSI model은 아래와 같이 정의
- \( p_{t}=f^{(i)}(t)+\epsilon \)
- \( t \in F \) is frame, \( p_{t} \in P \) is position coordinate at \( t \), \( \epsilon\sim N(0,\sigma^{2}) \) is gaussian noise
- \( p_{t}=f^{(i)}(t)+\epsilon \)
- tracked되고 linearly interpolated된 길이가 \( L \)인 trajectory \( S^{(i)}=\left\{t^{(i)},p_{t}^{(i)}\right\}_{t=1}^{L} \)가 주어질 때, nonlinear motion 모델링 작업은 함수 \( f^{(i)} \)를 fitting함으로써 해결
- gaussian process \( f^{(i)}\in GP(0,k(\cdot,\cdot)) \)를 따른다고 가정하면, \( k(x,x')=exp(-\frac{\left\|x-x'\right\|^{2}}{2\lambda^{2}}) \)는 radial basis function kernel
- \( \lambda \)는 trajectory의 smoothness를 조절하므로 trajectory의 길이와 연관되며, 단순하게 \( \lambda=\tau*log(\tau^{3}/l) \)로 정의
- radial basis function kernel은 gaussian kernel이라고도 불리며, 더욱 구체적으로 가우시안 형태를 취하는 커널
- gaussian process \( f^{(i)}\in GP(0,k(\cdot,\cdot)) \)를 따른다고 가정하면, \( k(x,x')=exp(-\frac{\left\|x-x'\right\|^{2}}{2\lambda^{2}}) \)는 radial basis function kernel
- 새로운 frame 세트 \( F^{*} \)가 주어지면, gaussian process의 특성에 의해 smoothed positions \( P^{*} \)는 아래와 같이 예측
- \( P^{*}=K(F^{*},F)(K(F,F)+\sigma^{2}I)^{-1}P \)
- \( K(\cdot, \cdot) \)은 \( k(\cdot, \cdot) \)에 기반한 공분산 함수
- \( P^{*}=K(F^{*},F)(K(F,F)+\sigma^{2}I)^{-1}P \)
- GSI를 통해 raw track의 noisy jitter포함 문제, linear interpolation의 motion information 무시 문제를 해결
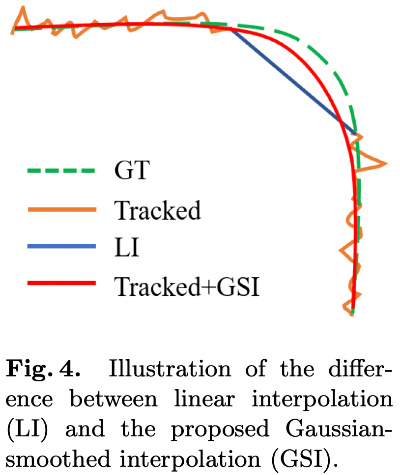
6. Experiment
- 아래의 환경에서 실험
- COCO dataset으로 pre-train된 YOLO-X를 detector로 이용
- datasets : MOT17, MOT20, Cityperson, ETHZ
- detection confidence threshold : 0.6
- NMS threshold(for inference set) : 0.8
- feature distance threshold : 0.45
- momentum : 0.9
- weight factor \( \lambda \) : 0.98
- hyperparameter \( \tau \) : 10
- maximum gap(allowed for interpolation) : 20 frames
- visualization sample

- Ablation Study on MOT17

- AFLink와 GSI의 효과

- MOT dataset에서의 성능 비교


7. Conclusion
- classic tracker인 DeepSORT를 다양한 측면에서 개선
- AFLink와 GSI algorithm 제시
- 다음과 같은 제한이 있음
- 다른 joint tracker나 appearance-free sepeate tracker에 비해 속도가 느림
- detection에서의 높은 threshold로 인해 MOTA가 낮음
- AFLink은 missing association은 잘 복원하지만 false association 문제에는 도움이 되지 않으며, ID가 뒤섞인 trajectories를 정확한 tracklet으로 나눌 수 없음
논문 링크
https://arxiv.org/abs/2202.13514
https://github.com/dyhBUPT/StrongSORT
참고 링크
728x90
반응형
'Paper Reading > Review' 카테고리의 다른 글
Contents
소중한 공감 감사합니다