Paper Reading/Review
[리뷰] Track to Detect and Segment: An Online Multi-Object Tracker
- -
728x90
반응형
이번에는 Multi-Object Tracking에 관련된 CVPR 2021에 게재된 논문인 TraDeS(Track to Detection and Segment: An Online Multi-Object Tracker)를 읽고, 리뷰해보고자 합니다.
사실, 교수님이 처음으로 읽으라고 주신게 이전 포스팅인 YOLOv1 이었는데, 바로 다음 읽을거리로 이걸 주셔서...ㅎㅎ (이하생략) 암튼 열심히 찾고 공부한 기분이었다.
Index
1. Background
1.1. Object Tracking
1.2. TBD
1.3. JDT
1.4. Cost Volume
1.5. DCN
1.6. CenterNet
1.7. re-ID
2. Abstract
3. Introduction
4. Preliminary
5. TraDeS Tracker
5.1. Overview
5.2. CVA module
5.2.1. Cost Volume
5.2.2. Tracking Offset
5.3. MFW module
5.3.1. Temporal Propagation
5.3.2. Feature Enhancement
5.4. Tracklet Generation
5.5. Training
6. Experiment
7. Conclusion
1. Background
1.1. Object Tracking
Object Tracking
0. 배경 지식 Object Detection Object Detection 1. 개념 영상 속에서 어떤 물체가 어디에 있는지 파악하는 것을 객체 탐지라고 합니다. 2. 예시 위 사진에서, 어떤 물체(사람, 버스, 자전거 등)가 어디(화면
alstn59v.tistory.com
1.2. TBD
Tracking By Detection의 약자로, detection과 tracking을 단계적, 독립적으로 수행하는 방식이다. 2단계 처리로 인해 end-to-end 최적화가 이루어지지 않으며, detection과 tracking의 결합을 위해 별도의 신경망도 사용한다. 따라서, 최근에는 JDT방식이 선호된다.

1.3. JDT
Joint Detection and Tracking의 약자로, backbone network는 공유하지만, detection과 tracking을 동시에 독립적으로 수행하는 방식이다. 일반적인 tracking loss(re-ID loss)는 공유하는 backbone을 훈련할 때 detection loss와 호환이 되지 않아 detection 성능에 부정적인 영향을 미친다. 그 이유는, tracking은 intra-class 분산을 최대화 하여 object를 구분하는 것이 목표지만, detection은 intra-class 차이를 최소화하고, inter-class 차이를 확대하는것이 목표이기 때문이다.
1.4. Cost Volume
두 이미지의 intensity 차이를 pixel 단위로 계산하여 similarity를 측정한 것을 하나의 volume으로 쌓은 것이다. 이미지 매칭에 이용된다.

1.5. DCN
Deformable Convolution Network의 약자로, CNN에서의 고정된 크기와 모양의 filter를 이용해서 feature를 추출하는 것이 아닌, flexible한 영역에서 feature를 추출하는 방식을 사용한다. 즉, feature map에서 규직적인 grid내의 값을 sampling을 하는 것이 아닌, 광범위한 grid cell의 값을 sampling하는 것이다. 따라서 filter의 크기를 학습하여 object의 크기에 맞춰 변화하게 되며, 다양한 크기의 object에 대한 detection 성능이 향상된다고 한다.

1.6. CenterNet
성능이 좋은 실시간 object detection 모델로, anchor box를 사용자가 정의하지 않고 사전 정의된 key point들을 예측 및 이용하여 bounding box 생성하는 방식을 이용하여 detection을 수행한다. 신경망에서 이미지를 연산하여 출력되는 feature는 서로 다른 key point들에 대하여 heatmap을 가지게 되는데, heatmap의 peak이 object의 중심으로 예측한다. 이 중심을 이용하여 bounding box의 좌표를 예측하는데, 각 중앙점은 고유한 width와 height를 가지므로 NMS를 사용하지 않는다. object를 classification할 때도 heatmap의 peak를 사용하게 된다.

input image I∈RH×W×3I∈RH×W×3에서 base feature f∈RHF×WF×64(HF=H4,WF=W4)f∈RHF×WF×64(HF=H4,WF=W4)는 backbone network ϕ(∙)ϕ(∙)에 의해 생성된다. head Conv branch에서 ff를 이용해 class-wise center heatmap P∈RHF×WF×NclsP∈RHF×WF×Ncls (NclsNcls는 class의 수)를 생성하고, 작업별(2D, 3D, mask, … etc) prediction map을 생성한다. 대략적인 model의 구조는 아래와 같다.

1.7. re-ID
re-identification
1. 개념 줄여서 re-ID라 하며, object를 재인식 하는 기술 영상에서 지속적으로 등장하는 object에 대해 재인식하여 동일한 ID를 부여할 수 있다면, tracking이 가능 유사한 object를 구분하거나, 다른 각도
alstn59v.tistory.com
2. Abstract
- TraDeS는 tracking 정보를 활용하여 end-to-end detection을 지원
- 대부분의 online multi-object tracker는 tracking 정보를 이용하지 않고, detection을 독립적으로 수행
- TraDeS는 현재 object detection과 segmentation을 개선하기 위해 tracking offset을 추론
- cost volume에 의해 계산되며, 이전 frame의 object에 대한 feature를 다음 frame으로 전파하는 데 사용
3. Introduction
- tracking 단서를 detection에 이용하여 detection 성능을 향상시키고, tracking이 그 혜택을 누리는 MOT 제안
- 현재 frame의 가려지거나 흐릿한 object는 이전 frame에서 식별되므로, 이전 frame의 정보를 이용하여 놓친 물체를 복구
- 두 frame에서 re-ID embedding의 similarity를 이용해 cost volume을 계산하고, tracking offeset을 예측하는 CVA(cost volume based association) module 제안
- tracking offset을 motion 신호로 사용하여 이전 frame에서 현재 frame으로 obejct의 feature를 전파하는 MFW(motion-guided feature warper) module 제안

4. Preliminary
- TraDeS는 object detector인 CenterNet을 기반으로 제작
- CenterNet 처럼 feature map의 각 point는 object의 중심이나 배경을 나타냄
- CenterNet에 추가적으로 데이터 연결을 위한 tracking offeset map OBOB를 예측하는 head branch를 추가하여 tracker를 구축
- OBOB는 시간 tt의 모든 point에서 이전 시간 t−τt−τ의 해당 point에 대해 시공간 변위 
- OB∈RHF×WF×2OB∈RHF×WF×2
5. TraDeS Tracker
5.1. Overview
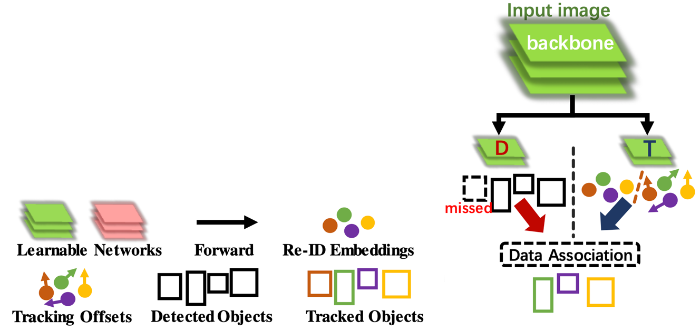
- 전체적인 구조는 아래와 같음

5.2. CVA module
- 전체적인 module의 작동과정은 아래와 같음

5.2.1. Cost Volume
- ItIt와 It−τIt−τ의 cost volume CC는 아래와 같이 계산
- Ci,j,k,l=e′ti,je′t−τk,l⊤∈RHC×WC×HC×WCCi,j,k,l=e′ti,je′t−τk,l⊤∈RHC×WC×HC×WC, (k,l)(k,l)은 It−τIt−τ의 point로, ItIt의 (i,j)(i,j)에 매칭
- CC를 구축하기 위해 embedding network σ(∙)σ(∙)를 이용하여 ItIt와 It−τIt−τ의 feature인 ftft와 ft−τft−τ에 대해 embedding etet추출
- et=σ(ft)∈RHF×WF×128et=σ(ft)∈RHF×WF×128
- 이때 CC의 계산을 효율적으로 하기 위해 etet를 down sampling한 e′te′t 이용
- e′t∈RHC×WC×128(HC=HF2,WC=WF2)e′t∈RHC×WC×128(HC=HF2,WC=WF2)
5.2.2. Tracking Offset
- ItIt의 (i,j)(i,j)에서 offset은 아래와 같이 계산
- Oi,j=[CHi,j⊤Vi,j,CWi,jM⊤i,j]⊤∈R2Oi,j=[CHi,j⊤Vi,j,CWi,jM⊤i,j]⊤∈R2, O∈RHC×WC×2O∈RHC×WC×2
- Step 1
- ItIt에 있는 object x의 중심 (i,j)(i,j)에 대해 It−τIt−τ의 모든 point와 matching similarity가 계산된 Ci,jCi,j를 CC에서 추출
- Ci,jCi,j를 HC×1HC×1, 1×WC1×WC kernel로 각각 max pool 하여 object x가 특정 height, width에서 등장할 확률이 담긴 CHi,j∈[0,1]HC×1CHi,j∈[0,1]HC×1, CWi,j∈[0,1]1×WCCWi,j∈[0,1]1×WC를 추출
- Step 2
- CHi,jCHi,j, CWi,jCWi,j 를 최종 tracking offset에 반영하기 위해 width와 height방향에 대해 각각 It−τIt−τ에서 실제 object x의 offset정보를 담은 template Mi,j∈R1×WCMi,j∈R1×WC, Vi,j∈RHC×1Vi,j∈RHC×1이용
- 계산에 이용되는 It−τIt−τ에서 실제 object x가 (∗,l)(∗,l), (k,∗)(k,∗)에 등장했을 때의 offset인 Mi,j,lMi,j,l, Vi,j,kVi,j,k는 아래와 같이 계산
- {Mi,j,l=(l−j)×s1≤l≤WCVi,j,k=(k−i)×s1≤k≤HC, s is stride value, 8.
- offset은 e를 기반으로한 C를 이용하여 구하므로, robust한 motion단서로 이용될 수 있음
5.3. MFW module
5.3.1. Temporal Propagation
- feature map을 전파하기 위해 DCN을 이용
- input으로 offset map OD∈RHF×WF×2K2와 이전 frame의 feature ft−τq를 가지고, output으로 전파된 feature map ˆft−τ을 가짐
- K는 kernel size
- input으로 offset map OD∈RHF×WF×2K2와 이전 frame의 feature ft−τq를 가지고, output으로 전파된 feature map ˆft−τ을 가짐
- OD를 구하기 위해 3×3크기의 convolution network γ(∙)에 OC를 통과
- 더 많은 motion 단서를 제공하기 위해 선택적으로 통합한 ft−ft−τ를 γ(∙)의 input으로 제공
- CenterNet에 기반한 feature를 이용하기 때문에, center-attentive feature ˉft−τ∈RHF×WF×64를 아래와 같이 계산
- ˉft−τq=ft−τq∘Pt−τagn
- q is index of channel (1~64)
- ∘는 Hadamard production
- Pt−τ는 class-agnostic heatmap
- ˉft−τq=ft−τq∘Pt−τagn
- 전파된 feature map은 아래와 같이 계산
- ˆft−τ=DCN(OD,ˉft−τ)∈RHF×WF×64

5.3.2. Feature Enhancement
- 가려지거나 흐린 물체에 대한 detection 실패를 막기 위해, ˉft−τ를 집계하여 ft를 강화한 feature인 ˜ft−τ 제안
- ˜ftq=wt∘ftq+∑Tτ=1wt−τ∘ˆft−τq
- wt∈RHF×WF×1는 시간 𝑡에서의 adaptive weight, softmax 함수로 예측
- ∑Tτ=0wt−τi,j=1, T는 aggregation을 위해 사용한 이전 feature의 수
- ˜ftq=wt∘ftq+∑Tτ=1wt−τ∘ˆft−τq
- head network에서 현재 frame에 detection box와 mask를 그리기 위해 활용
- complete한 tracklet 생성
- FN 감소, 높은 MOTA와 IDF1 달성에 도움
5.4. Tracklet Generation
- ˜ft를 이용하여 생성된 중심이 (i,j)인 detection box나 mask d는 아래 2단계의 data association 과정을 통해 t−1시점의 tracklet에 결합되어 tracklet을 업데이트
- DA Round (i) : d의 width와 height의 기하평균인 (i,j)+OC를 반지름으로 가지는 영역에서, d와 가장 가까운 매칭되지 않은 tracklet에 매칭 시도
- DA Round (ii) : 위의 단계에서 d가 매칭에 실패하면 매칭되지 않거나 이전의 모든 tracklet embedding과 eti,j에 대해 cosine similarity를 계산해서 threshold 값 보다 높은 tracklet에 매칭 시도
- data association 과정에서 tracklet 업데이트에 실패하면 새로운 tracklet 생성
- 결국 이전 feature와 offset을 연관시켜 장기 데이터 연관이 가능하도록 함
- 2D, 3D dection을 위해 CenterNet과 동일한 head network 이용
- instance segmentation을 위해 CondInst의 head network 참조
5.5. Training
- TraDeS 모델의 전체 Loss는 아래와 같음
- LTraDeS=LCVA+Ldet+Lmask
- Ldet는 2D, 3D detection loss
- XingyiZhou,DequanWang,andPhilippKra ̈henbu ̈hl.Objects as points. arXiv preprint arXiv:1904.07850, 2019.
- Lmask는 instance segmentation loss
- Zhi Tian, Chunhua Shen, and Hao Chen. Conditional convo- lutions for instance segmentation. In ECCV, 2020.
- LCVA는 CVA module의 loss로, 아래와 같이 계산
- LCVA=−1∑ijklYijkl∑ijkl{(1−CWi,j,l)βlog(CWi,j,l)+(1−CHi,j,k)βlog(CHi,j,k)if Yijkl=10otherwise
- Yijkl은 It의 (i,j)에 위치한 object x가 It−τ의 (k,l)에 존재할 때 1, β는 focal loss의 hyper-parameter
- CWi,j,l와 CHi,j,k가 1에 접근하도록 최적화되어 있는데, object가 이전 frame의 object에 access하면서 다른 것들은 제거시키는 의미
- LCVA는 object x에 대해 offset의 예측 확률값 \( C^{W}_{i,j,l} \)와 \( C^{H}_{i,j,k} \)가 높을수록 0에 가까워지는데, 이는 곧 예측을 잘 할수록 loss가 떨어짐을 의미
- re-ID를 위한 의 생성을 위한 만이 CVA에서 유일하게 학습 가능한 부분
- 일반적인 re-ID loss처럼 를 직접 감독하는 대신, cost volume 에 대해 감독
6. Experiment
- 각 모듈의 적용에 따른 성능 비교

- DA Round (ii)의 적용 유무에 따른 성능 비교

- motion 단서의 활용 유무에 따른 성능 비교

- 이전 feature를 얼마나 사용하느냐에 따른 성능 비교

- MOT dataset에서 2D tracking시, 다른 model과의 성능 비교


- nuScenes dataset에서 2D tracking 결과

- nuScenes dataset에서 3D tracking시, 다른 model과의 성능 비교


- MOTS dataset에서 instance sementation시, 다른 model과의 성능 비교


- YouTube-VIS dataset에서 instance sementation시, 다른 model과의 성능 비교


7. Conclusion
- intra-class 분산과 inter-class 차이를 모두 강조하는 방식을 통해 tracking과 detection의 상호작용으로 성능을 향상시키는 JDT model 제시
- CVA, MFW module 제안
- low FPS영상과, 가려지거나 흐릿한 물체에 대해서도 검출 가능
- 성능과 소요시간에서 SOTA 달성
논문 링크
https://arxiv.org/abs/2103.08808
https://jialianwu.com/projects/TraDeS.html
https://github.com/JialianW/TraDeS
https://github.com/alstn59v/TraDeS-CUDA11
참고 링크
https://throwexception.tistory.com/1260
https://eehoeskrap.tistory.com/183
https://velog.io/@garam/Fine-tuning-vs-Transfer-learning-vs-Backbone#backbone
https://blog.naver.com/dnjswns2280/222073493738
https://deep-learning-study.tistory.com/575
https://eehoeskrap.tistory.com/406
https://gaussian37.github.io/vision-detection-centernet
https://pajamacoder.tistory.com/3
https://cvml.tistory.com/3
https://velog.io/@heaseo/Focalloss-설명
728x90
반응형
Contents
소중한 공감 감사합니다