Paper Reading/Review
[리뷰] Attention Mechanisms in Computer Vision: A Survey
- -
728x90
반응형
이번에는 Attention 기술이 Computer Vision 영역에서는 어떻게 쓰이고 있는지 소개를 하는 2020년에 게재된 논문인 Attention Mechanisms in Computer Vision: A survey를 읽고, 리뷰해보고자 합니다.
논문이 Article 성격에 가까운 Survey 논문이라, 어렵고 원리 및 아이디어의 내용이 주가 아닌, 소개 정도의 내용이어서 리뷰의 성격보다는 번역 및 요약의 성격이 될 것 같습니다.
Index
1. Abstract
2. Introduction
3. Methods
3.1. Overview
3.2. Channel Attention
3.3. Spatial Attention
3.4. Temporal Attention
3.5. Branch Attention
3.6. Channel & Spatial Attention
3.7. Spatial & Temporal Attention
4. Future Directions
1. Abstract
- 인간은 복잡한 장면에서 자연스럽고 효과적으로 두드러진 영역을 찾을 수 있는데, 컴퓨터 비전 영역의 인공지능에 이러한 측면을 모방하기 위해 attention이라는 방법을 이용하였으며, 입력 이미지의 feature를 기반으로 한 weight 조정 과정으로 생각할 수 있음
- attention은 classification, detection, segmentation, understanding, generate, 등 많은 영역에서 성과를 보임

2. Introduction
- 입력 데이터에서 중요한 영역을 강조하고, 그렇지 않은 영역을 무시하는 방법을 attention이라 함
- 복잡한 데이터를 효율적이고 효과적으로 분석하고 이해하는 데 도움을 주기 위해 사용
- CV 영역에서 attention은 input image 영역의 중요성에 따라 적응적으로 가중치를 부여하는 과정으로 생각할 수 있음
- 지난 10년 동안 CV 영역에서 점점 더 중요한 역할을 했으며, CNN을 대체하고 더 성능이 좋으면서 일반적인 구조가 될 잠재력이 있음

3. Methods
3.1. Overview
- Attention에는 다양한 종류가 있으며, 이를 matrix로 표현해 attention 해야할 부분을 시각화 하면 아래와 같음
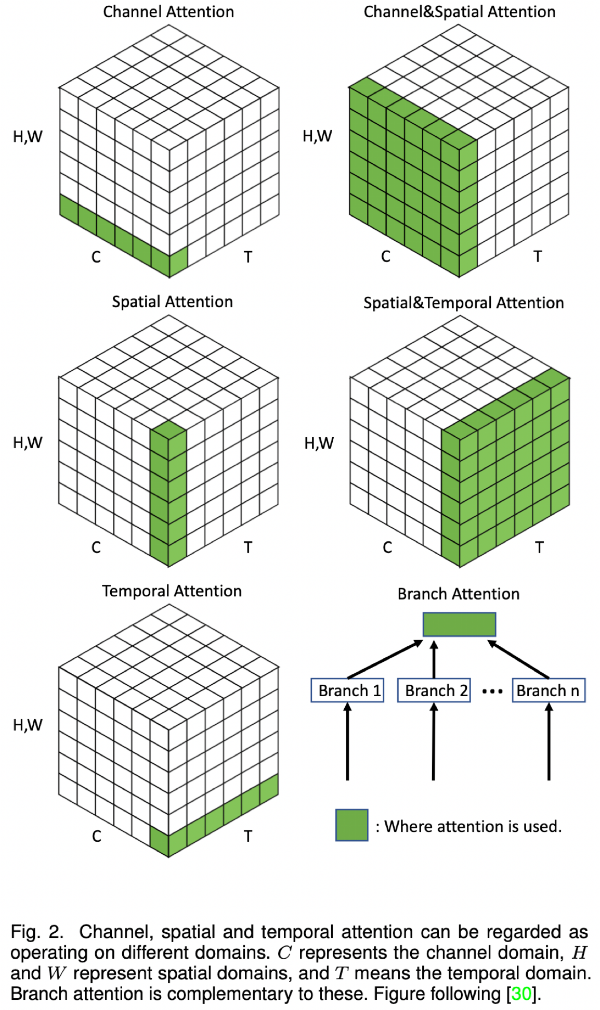
- 위의 그림에 나온 여러 방법들에 대한 실제 작품?실예시? 에 대해 아래 그림으로 볼 수 있음

- 보통 attention은 아래의 수식으로 표현 가능
- \( Attention=f(g(x),x) \)
- \( g(x) \)는 구분 가능한 영역에 attention을 생성하는 것
- 즉, \( g(x) \)로 생성된 attention을 기반으로 입력값 \( x \)를 처리하는 것
- \( Attention=f(g(x),x) \)
- self-attention은 아래와 같이 표현 가능
- \( Q,K,V=Linear(x),\ g(x)=Softmax(QK),\ f(g(x),x)=g(x)V \)
3.2. Channel Attention
- DNN에서 다른 feature map의 다른 channel은 보통 다른 물체를 뜻함
- channel attention은 각 채널의 weights를 adaptive하게 조정하여 object를 선택하므로, attention 할 것을 결정할 수 있음
- SENet을 시작으로, 이를 개선한 GSoP-Net, SRM, GCT, ECANet, FcaNet과 같은 방법이 있음
- SENet : feature를 squeeze와 excitation 모듈로 나눠서 계산, 계산 cost는 적지만 복잡한 정보를 잡아내기에는 방식이 simple하다는 단점 존재
- GSoP-Net : global average pooling이 잡아내지 못하는 global 정보를 잡기위해 squeeze 모듈을 개선
- FcaNet : squeeze 모듈만으로는 표현력이 떨어지기 때문에, discrete consine transform에 기반한 방법을 제안
- ECANet : W와 input간의 상호연관을 모델링하지 못하는 문제를 개선하기 위해 excitation 모듈을 1D conv를 이용하여 개선
- SRM : input feature의 평균과 표준편차를 이용하여 global 정보를 잡는데 성능을 향상
- GCT : conv layer다음에 SE block을 사용하는 것은 계산 cost가 높기 때문에, channel 별 관계를 명확히 하기 위해 L2-norm으로 global 정보를 수집하는 Gated Channel Transformation 제안
3.3. Spatial Attention
- spatial attention은 adaptive한 공간 영역을 선택하는 방법으로, 어느 공간에 attention을 해야할지 정하는 방법
- RAM을 시작으로, 이를 개선한 Glimpse Network와 같은 방법이 있음
- RAM : CNN의 높은 계산 cost를 대체하기 위해, 중요한 지역을 attention하기 위한 RNN과 강화학습을 결합한 방법 제안
- STN을 시작으로, 이를 개선한 DCN과 같은 방법이 있음
- STN : CNN은 다양한 기하학적 변형에 대한 불변성이 부족한 것을 극복하기 위해 명시적인 절차를 사용하여 attention하는 방법 제안
- Self-attention을 시작으로, 이를 개선한 Vision Transformer와 같은 방법이 있음
- Glimpse Network : 인간이 힐끗힐끗 보면서 추론하는 것을 모방하여, input으로 glimpse를 사용하여 hidden state를 업데이트하고, 각 단계에서 새로운 object와 다음으로 glimpse할 위치를 예측하는 방법 제안
- Vision Transformer : NLP에서 성과를 낸 transformer 구조를 CV에 적용한 것으로, CNN보다 더 나은 결과를 보여줌
3.4. Temporal Attention
- temporal attention은 video에서 attention을 해야할 시간대를 동적으로 선택하는 방법으로, cross-frame 종속성을 포착하기 위해 이용
- GLTR, TAM과 같은 방법이 있음
- GLTR : self-attention을 기반으로 하여 frame간의 상호 작용을 잡아내기 위한 계산을 효율적으로 하고, occlusion과 noise를 극복하기 위해 제안
- TAM : global 정보를 잡아내기 위해 self-attention 대신 adaptive-kernel을 사용한 GLTR 보다 시간 복잡도가 낮은 방법 제안
3.5. Branch Attention
- branch attention은 동적으로 분기를 선택하는 방법으로, multi-branch 구조와 함께 사용
- Highway network, SKNet, CondConv, Dynamic Convolution과 같은 방법이 있음
- Highway Network : LSTM처럼 깊은 네트워크에서 layer를 가로질러 정보가 이동하도록 하는 방법 제안
- SKNet : 인간 시각처럼 입력 자극에 따라 수용체의 크기를 조정하는 것을 모방한 방법 제안
- CondConv : CNN의 표현력을 높이기 위해 multi-branch 구조의 장점 활용
- Dynamic Conv : lightweight CNN의 표현력 감소 문제를 해결하기 위해 k개의 병렬 kernel을 사용한 동적 conv연산 제안
3.6. Channel & Spatial Attention
- 중요한 object와 영역을 모두 적응적으로 선택하도록 channel attention과 spatial attention의 장점을 결합한 방법
- CBAM, BAM, scSE를 시작으로, 이를 개선한 Triplet Attention, Coordinate attention, DANet, RGA과 같은 방법이 있음
- CBAM : channel attention과 spatial attention을 series로 쌓아 하나 이상의 pooling을 이용하는 conv block 제안
- BAM : 확장된 CNN과 ResNet이 제안한 bottleneck을 이용하여 bottleneck attention 제안
- scSE : SE block에 spatial SE block을 추가하여 영역과 channel의 정보를 결합하는 spatial-channel SE block 제안
- DANet : channel attention과 spatial attention을 병렬로 사용하여 장거리에서의 종속성을 찾아내는 방법 제안
- RGA : pairwise relation이 제공하는 global 구조 정보를 attention하는 방법 제안
- Residual Attention Network를 시작으로, 이를 개선한 SimAM, SPNet과 같은 방법이 있음
- SimAM : channel과 spatial영역에서 다양한 attention weight을 배워 3D weight를 직접 추정하는 매개변수가 필요없는 방법 제안
- SPNet : spatial pooling은 장거리 의존성을 잡아내는 능력을 제한하는 작은 영역에서만 작동하는데, 이를 수평, 수직 영역에서 장거리 문맥정보를 인코딩할 수 있는 strip pooling 방법 제안
- Triplet Attention : height, width, channel의 상호작용을 잡아내는 방법 제안
- Coordinate attention : 장거리 의존성을 보존하기 위해 위치 정보를 channel attention에 포함시키는 방법 제안
- Residual Attention Network : end-to-end 학습 방식의, attention과 residual connection을 결합한 방법 제안
3.7. Spatial & Temporal Attention
- 중요한 영역과 프레임을 모두 적응적으로 선택하도록 spatial attention과 temporal attention의 장점을 결합한 방법
- RSTAN, STA, STGCN과 같은 방법이 있음
- RSTAN : RNN과 같이 현재 state에서 예측한 것과 관련이 있는 영역과 프레임을 식별하는 방법 제안
- STA : 시공간의 차별적인 부분을 활용하여 각 영역에 대해 attention score를 할당하여 시공간적 관계를 잡아내는 방법 제안
- STGCN : frame내의 영역별 관계와 frame간이 시간적 관계를 모델링하기 위해 각 frame을 patch로 분할하여 이에 대한 그래프를 이용한 conv 네트워크 제안
4. Future Directions
- 작업의 영역에 적합하게 설계해야 하는데, 모든 영역에서 활용할 수 있는 일반적인 attention block에 대해 연구 필요
- 의료나 자율주행 같은 안전이 중요한 영역에서는 더 높은 수준의 적합성과 성능이 필요
- pre-trained model과 attention model을 조합하는 방법에 대한 연구 필요
- attention model에 Adam optimization이 잘 작동하지만, 다른 optimization 방법에 대한 연구 필요
- CNN은 간단하고 균일한 구조가 있지만, attention 모델은 그렇지 못하여 배포가 어려움
논문 링크
https://arxiv.org/pdf/2111.07624.pdf
https://github.com/MenghaoGuo/Awesome-Vision-Attentions
참고 링크
728x90
반응형
'Paper Reading > Review' 카테고리의 다른 글
Contents
소중한 공감 감사합니다