Paper Reading/Review
[리뷰] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- -
728x90
반응형
이번에는 최근 CV 분야에서도 SOTA를 달성하고 있는 Transformer에 관련된 ICLR 2021에 게재된 논문인 ViT(An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale)를 읽고, 리뷰해보고자 합니다.
Index
1. Background
1.1. Attention, Self-Attention, Transformer
1.2. Inductive Bias
2. Abstract
3. Introduction
4. Related Work
4.1. Transformer
4.2. Attention in CV
4.3. On the relationship between self attention and convolutional layers
4.4. Self-Attention combine CNN
5. Method
5.1. Whole Architecture
5.2. Linear Projection
5.3. Class Embedding
5.4. Positional Embedding
5.5. Multi-head Attention
5.6. Inductive Bias
5.7. Hybrid Architecture
5.8. Fine-Tuning And Higher Resolution
6. Experiment
7. Conclusion
1. Background
1.1. Attention, Self-Attention, Transformer
Attention, Self-Attention, Transformer
1. Attention 1.1. 개념 input sequence가 길어지면 output sequence의 정확도가 떨어지는 것을 보정해주기 위한 등장한 기법 데이터 전체를 살펴보고 집중해서 살펴볼 위치를 정하는 매커니즘 decoder에서 출
alstn59v.tistory.com
1.2. Inductive Bias
Inductive Bias
1. 개념 어떤 모델이 지금까지 만나보지 못했던 상황에서, 입력값에 대한 예측을 정확하게 하기 위해 사용하는 추가적인 가정 예를 들어 CNN은 locality와 translation invariance가 있음 참고 링크 https://a
alstn59v.tistory.com
2. Abstract
- 현재 transformer 구조는 NLP 영역에서 사실상 표준이 되었음
- 그러나, CV 영역에서는 CNN과 함께 쓰는 등의 제한적 활용 상태임
- 따라서 본 논문에서는 CNN에 대한 의존 없이, transformer 구조가 classification에서 잘 작동함을 보여줌
3. Introduction
- CV 영역에서 CNN과 self-attention을 결합하거나, CNN을 attention으로 대체하는 연구는 있었지만, GPU의 가속을 적용하지 못하는 상태였음
- ResNet 기반의 모델이 여전히 SOTA인 상태였음
- NLP 분야의 transformer 구조에서 영감을 받아 image에 transformer를 직접 적용
- image는 patch로 나뉘어지며, 이 patch가 corpus의 token처럼 input으로 사용
- transformer는 inductive bias가 없어 데이터 셋의 규모가 커야함
- data augmentation의 결과(회전, 이동 등)와 같은 다양한 경우에 대한 데이터 필요
4. Related Work
4.1. Transformer
- 일반적으로 large text corpus에 pre-train(self-supervised learning) 한 다음, specific한 dataset에 전이학습을 하는 방법을 주로 사용
- BERT : denoising self-supervised pre-training task 사용
- GPT : language modeling을 pre-training trask로 사용
- 연산이 효율적임
- input sequence의 길이에 구애받지 않아, scalability가 좋음
4.2. Attention in CV
- 각 pixel과 모든 pixel의 attention을 생각해 볼 수 있지만, 계산 비용이 굉장히 높음
- 근사화를 사용한 local multi-head dot-product self attention block, sparse transformer 와 같은 연구가 등장했으나, GPU 가속을 사용하지 못하였음
- 다양한 크기의 block이나 같은 좌표축을 따라서만 attention을 적용하는 방법도 등장하였으나, 마찬가지로 GPU 가속을 사용하지 못하였음
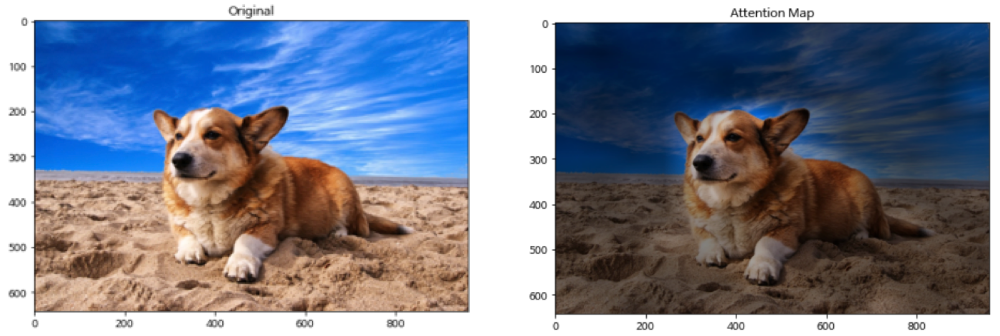
4.3. On the relationship between self attention and convolutional layers
- 모든 pixel마다 attention을 하기 힘든 문제를, 이미지를  픽셀 크기의 patch로 분할하여, 이 patch에 attention을 적용
- ViT와 매우 유사하지만, ViT는 pre-training을 이용한다는 차이점 존재
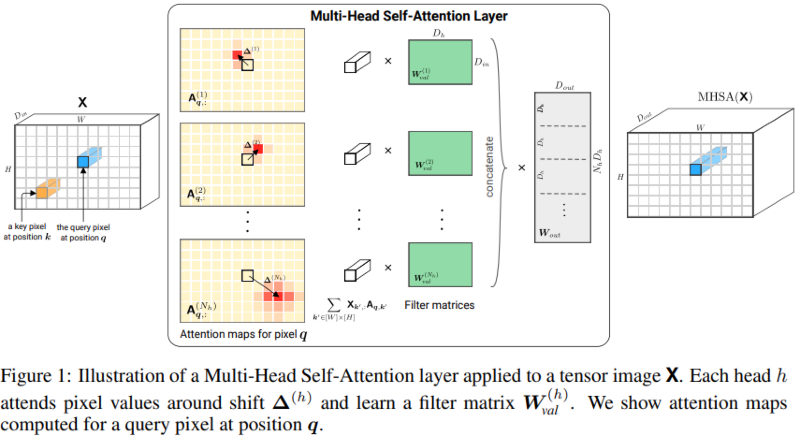
4.4. Self-Attention combine CNN
- Self-Attention combine CNN
- attention을 이용해 feature map을 augment하는 연구
- CNN의 output에 self-attention을 적용한 연구들
- imageGPT
- 이미지의 resolution과 color space(dimension)을 낮춘 뒤, transformer를 적용
- 비지도 학습인 GAN 모델의 한 종류
5. Method
5.1. Whole Architecture
- NLP transformer의 scalability와 implementation의 효율성을 가능하게 하기위해 최대한 원래의 구조를 따름

- \( LN \) = Layer-norm, \( MLP \) = Multi Layer Perceptron, \( MSA \) = Multi-head Self-Attention
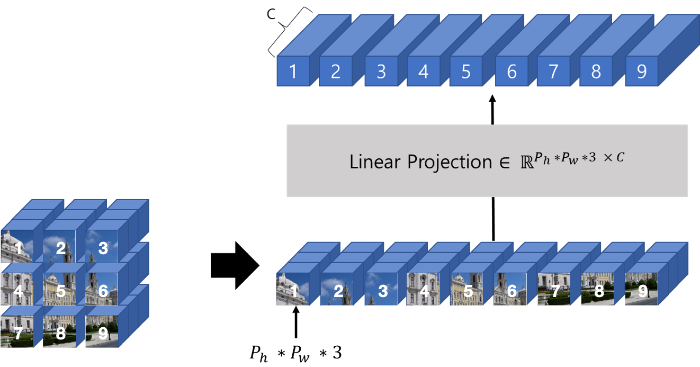
5.2. Linear Projection
- \( x \in \mathbb{R}^{H \times W \times C} \)인 이미지 를 token화 시키기 위해, 이미지를 \( N \)개의 \( P \times P \times C \) 크기의 patch로 분할
- 이것을 1D로 reshape한 latent vector를 이용
- NLP의 transformer의 input sequence는 D차원의 vector이므로, Linear Projection이라는 과정을 추가하여 patch embedding이라는 아래 형태의 D차원 vector 제작
- \( z0=[x_{class}; x^{1}_{p}E; x^{2}_{p}E; \dots; x^{N}_{p}E]+E_{pos} \)
- \( E \in \mathbb{R}^{(P^{2} \times C) \times D} \), \( E_{pos} \in \mathbb{R}^{(N+1) \times D} \)
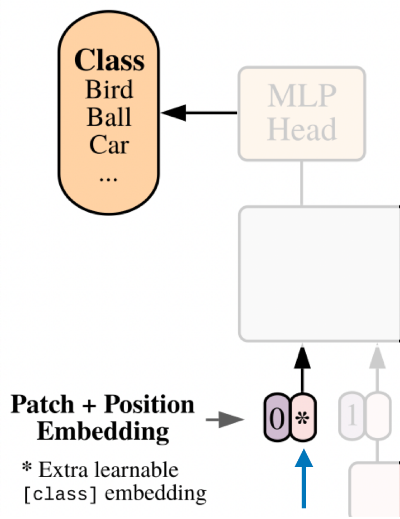
5.3. Class Embedding
- BERT의 [class] 토큰과 비슷하게, Linear Projection의 결과에 learnable한 class embedding을 이용
5.4. Positional Embedding
- 모델이 이미지의 구조를 학습할 수 있도록 함
- 원래 2D 위치 정보를 사용하려 하였으나, 성능 향상이 보이지 않아 학습 가능한 1D 위치 정보를 사용
- 즉, transformer의 encoder에 입력으로 class embedding, positional embedding, patch embedding이 사용됨
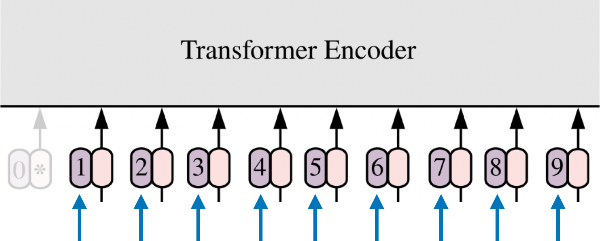
5.5. Multi-head Attention
- 여러 개의 attention layer를 병렬로 이용
- 모호한 정보에 대한 인코딩을 각 layer별로 다른 관점에서 정보를 수집하여 보완
- 집단 지성과 같이, 최종적으로 연관성이 높은 단어에 focus하는 효과

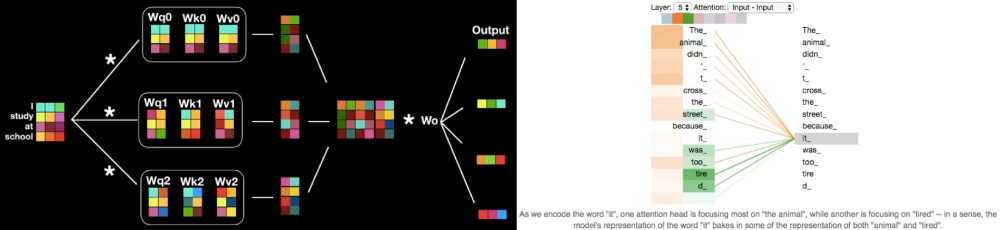
5.6. Inductive Bias
- CNN은 locality, two-dimensional neighborhood structure, translation equivariance와 같은 inductive bias 존재
- Locality(=Locality of Pixel Dependencies) : 이미지를 구성하는 특징들은 이미지 전체가 아닌 일부 지역들에 근접한 픽셀들로만 구성되고 근접한 픽셀들끼리만 종속성을 갖는다는 가정
- 아래 그림에서 '코'라는 특징은 파란색 사각형 안에 있는 픽셀값에서만 표현되고, 해당 픽셀들끼리만 관계를 가짐
- 빨간색 사각형 안의 픽셀들은 파란색 사각형 안의 픽셀과는 종속성이 없음
- 즉, 종속성을 갖는 픽셀들은 local하게 존재
- Convolution 연산은 이러한 이미지의 locality 특징에 잘 부합하는 방식으로 동작.
- Translation Equivariance : 입력의 위치 변화에 따라 출력 또한 입력과 동일하게 변화하는 것
- Convolution 연산은 Translation equivariant하다는 특성을 가짐
- Locality(=Locality of Pixel Dependencies) : 이미지를 구성하는 특징들은 이미지 전체가 아닌 일부 지역들에 근접한 픽셀들로만 구성되고 근접한 픽셀들끼리만 종속성을 갖는다는 가정
- ViT는 전체 정보를 고려하므로 CNN과 같은 inductive bias가 존재하지 않아, data-driven training으로 이 문제를 해결

5.7. Hybrid Architecture
- patch embedding을 구할 때 raw 이미지를 이용하여 patch를 생성하는 대신, CNN을 이용한 feature map을 input sequence로 이용 가능
- 특별한 경우 patch의 크기는 \( 1 \times 1 \)을 가질 수 있음
- input sequence가 feature map을 flatten하여 transformer의 차원으로 projection한 것을 의미
- class embedding, position embedding은 이전과 동일한 방법 적용
5.8. Fine-Tuning And Higher Resolution
- 큰 데이터 셋에서 pre-train하고, 더 작은 downstream task에서 fine-tuning 수행
- pre-train 시 보다, 더 높은 해상도의 이미지로 fine-tuning하는 것이 더 좋은 결과를 가져옴
- 대신 기존의 positional embedding이 더 이상 의미가 없어지게 되므로, 입력 이미지 크기 내 patch의 위치에 맞게 positional embedding도 2D interpolation을 적용
- ViT 내에서 수동적으로 이미지의 2차원 구조에 대한 inductive bias를 추가
- pre-train된 prediction head를 제거하고, 0으로 초기화된 \( D \times K \) feed-forward layer를 붙여줌
- \( K \)는 downstream class의 개수

6. Experiment
- 다음과 같은 환경에서 실험
- pre-training : ImageNet, ImageNet-21K, JFT 이용
- transfer learning : ImageNet, CIFAR 10/100, Oxford-IIIT Pets 등 이용
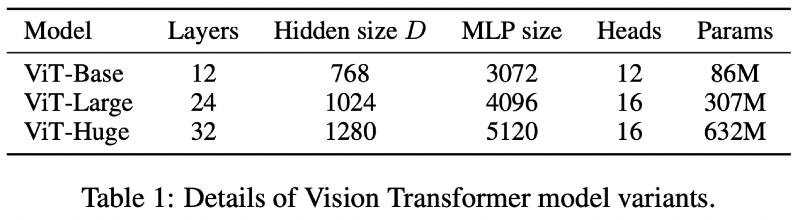
- Model Variants
- Inspecting Vision Transformers
- ViT는 가장 하위의 layer에서도 전체 이미지에 대한 정보를 통합할 수 있음
- 낮은 Network depth에서도 attention을 통해 global 하게 정보를 사용할 수 있음
- depth가 증가함에 따라 attention distance도 증가

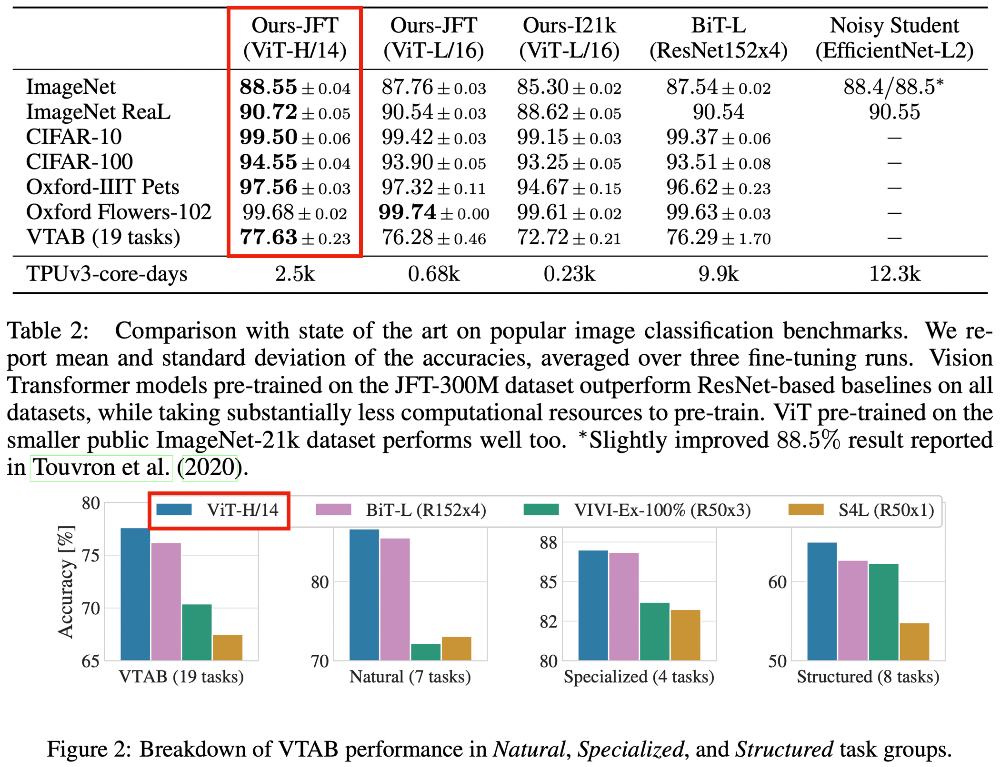
- Comparison to SOTA
- 모든 데이터셋에서 BiT-L과 비슷하거나 더 나은 수치를 보여줌
- 학습한 cost가 낮음
- Pre-training Data Requirements
- 중간 크기의 데이터셋에서 학습했을 때, ResNet보다 약간 낮은 수치의 정확도를 보이는데, 이는 inductive bias가 부족함을 의미
- 그러나, 큰 데이터셋에서 사전 학습했을 때 충분히 학습이 되어 잘 작동함을 보여줌
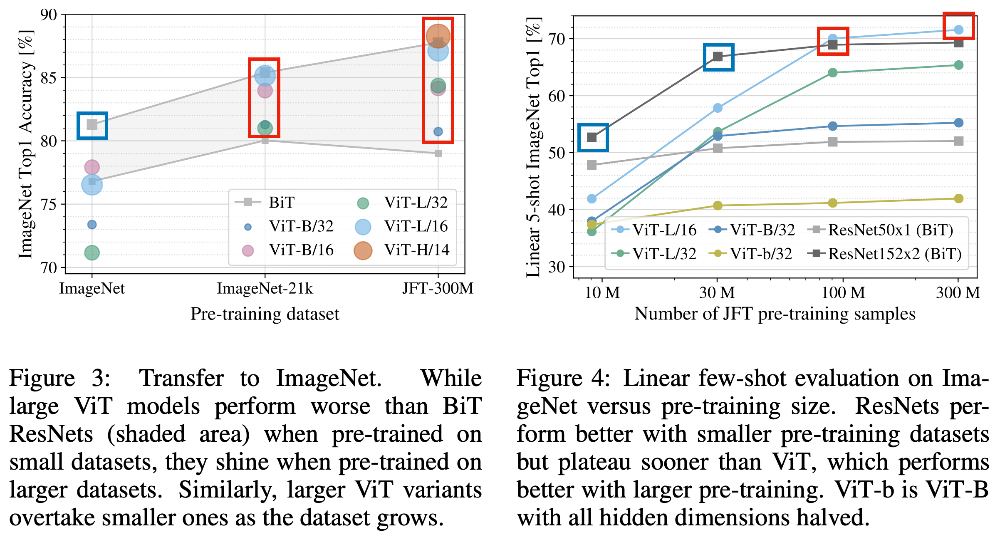
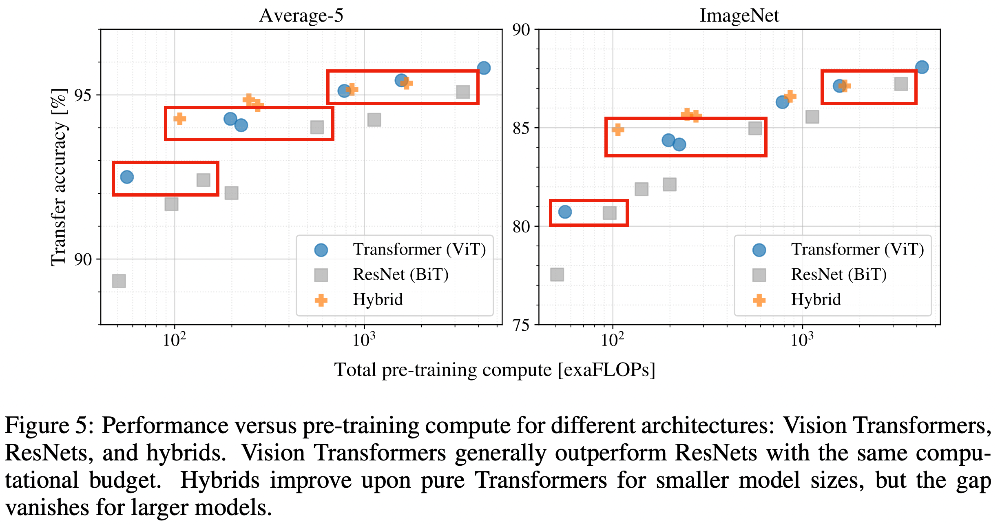
- Scaling Study
- ResNet보다 동일한 성능을 내기 위해 반 정도의 컴퓨팅이 필요
- 하이브리드 모델이 적은 computing cost에서는 ViT를 능가하지만, cost를 늘리게 되면 큰 차이가 없음
- 모델이 saturate되지 않으며, 스케일링이 가능nuScenes dataset에서 3D tracking시, 다른 model과의 성능 비교MOTS dataset에서 instance sementation시, 다른 model과의 성능 비교YouTube-VIS dataset에서 instance sementation시, 다른 model과의 성능 비교
7. Conclusion
- 기존 연구와 달리 직접적으로 이미지에 transformer 구조를 사용한 방법을 제안
- 대규모 데이터 셋으로 사전학습을 통해 SOTA 달성
- 계산 cost가 상대적으로 낮음
- 개선해야할 사항
- recognition 이외의 분야에 transformer 적용
- 사전학습 방법에 대해 추가 연구 필요(self-supervision과 연결)
- 데이터가 커도 모델이 포화되지 않는것을 통해, 더 나은 성능에 대해 실험 필요
논문 링크
https://arxiv.org/abs/2010.11929
https://github.com/google-research/vision_transformer
참고 링크
https://melona94.tistory.com/8
http://mergerity.co.kr/blog/?idx=12523847&bmode=view
https://glee1228.tistory.com/3
https://gaussian37.github.io/dl-concept-attention
https://www.youtube.com/watch?v=mxGCEWOxfe8
https://velog.io/@heaseo/Focalloss-설명
728x90
반응형
'Paper Reading > Review' 카테고리의 다른 글
| [리뷰] MOTR: End-to-End Multiple-Object Tracking with TRansformer (0) | 2023.02.01 |
|---|---|
| [리뷰] ByteTrack: Multi-Object Tracking by Associating Every Detection Box (0) | 2023.01.17 |
| [리뷰] Attention Mechanisms in Computer Vision: A Survey (1) | 2022.12.20 |
| [리뷰] Track to Detect and Segment: An Online Multi-Object Tracker (0) | 2022.07.30 |
| [리뷰] You Only Look Once: Unified, Real-Time Object Detection (0) | 2022.07.08 |
Contents
소중한 공감 감사합니다