Paper Reading/Review
[리뷰] You Only Look Once: Unified, Real-Time Object Detection
- -
728x90
반응형
처음 해보는 티스토리 블로그 포스팅이라 레이아웃이 많이 어색할 수 있지만, 내용만큼은 열정을 다해서 써봅니다.
아직은 졸업 직전인 학부생이지만, 3월부터 Lab에 출근을 해서 기초지식을 공부하다가 지금에서야 처음으로 Object Detection에 관련된 hot한 논문을 첫 논문으로 읽고, 리뷰해보고자 합니다.
목차
1. 배경 지식
1.1. Object Detection
1.2. IoU
1.3. NMS
1.4. Classification Evaluation Metrics
1.5. mAP
2. Abstract
3. Introduction
3.1. YOLO
3.2. Overview
4. Unified Detection
4.1. Object Detection Process
4.2. Network Design
4.3. Training
4.4. Inference
4.5. Limitations
5. Experiment
6. Conclusion
1. 배경 지식
1.1. Object Detection
Object Detection
1. 개념 영상 속에서 어떤 물체가 어디에 있는지 파악하는 것을 객체 탐지라고 합니다. 2. 예시 위 사진에서, 어떤 물체(사람, 버스, 자전거 등)가 어디(화면의 가운데, 우측 하단 등에 box 표시)에
alstn59v.tistory.com
1.2. IoU
Intersection of Union
1. 개념 줄여서 IoU라 하며, 영상에서 Ground Truth에 해당하는 bounding box와 model이 예측한 bounding box의 겹치는 정도를 계산한 값 즉, 예측한 결과가 얼마나 정답과 일치하는지를 나타냄 2. 계산 방법
alstn59v.tistory.com
1.3. NMS
Non-Maximum Suppression
0. 배경지식 IoU Intersection of Union 1. 개념 줄여서 IoU라 하며, 영상에서 Ground Truth에 해당하는 bounding box와 model이 예측한 bounding box의 겹치는 정도를 계산한 값 즉, 예측한 결과가 얼마나 정답과 일치
alstn59v.tistory.com
1.4. Classification Evaluation Metrics
Classification Evaluation Metrics
1. 개념 Confusion Matrix라 하며, model의 성능을 평가하기 위해서는 여러가지 지표들을 계산해야 하는데, 계산에 이용되는 값들을 정리한 표 2. 기본 지표 예측 결과 (Predict Result) Positive Negative 실제 상
alstn59v.tistory.com
1.5. mAP
mean Average Precision
1. 개념 줄여서 mAP라 하며, 각 class에 대해 예측한 것의 average precision에 평균을 취해준 것 값이 클수록 성능이 좋음 Precision-Recall curve의 아래 면적과 같은 값
alstn59v.tistory.com
2. Abstract
- 본 논문에서는 Object Detection의 새로운 접근 방식을 제시
- Object Detection 문제를 공간적으로 분리된 bounding box와 class probability에 대한 regression 문제로 정의
- base model이 45 fps의 처리속도를 가짐(light model은 155 fps의 처리 속도)
- 영상의 배경영역에 대한 false positive 예측이 R-CNN에 비해 덜함
- 배경에 노이즈가 있을 때, 물체라고 잘못 인식하는 상황
- 기존의 다른 Object Detection model 대비 mAP를 2배 달성
- Object의 일반적인 표현을 학습
3. Introduction
3.1. YOLO
- 사람은 영상을 한 번만 보고도, 어떤 물체가 어디에 있는지 단번에 알아차릴 수 있음
- 이전의 Detection 시스템은 classifier를 수정하여 Detection에 사용
- DPM은 sliding windows 방법 사용
- R-CNN은 region proposal 방법 사용
 |
 |
| sliding windows | region proposal |
- bounding box 표시와 class probability 구하는 문제를 단일 CNN으로 해결하여 성능 향상
- 영상 전체에 대해 추론하고, 표현을 학습
- 전체를 본다면, 조금 더 global한 feature를 반영할 수 있을 것이라 생각
- 배경에 대한 error가 감소하였지만, localization error가 높아지는 결과 발생
3.2. Overview
- 단일 convolution network를 통한 작동
- 224*224 크기의 영상에서 잡아내지 못하는 feature를 잡아내기 위해, 크기를 448*448로 resize
- bounding box와 class probability를 regression으로 예측
- NMS를 이용하여 최종 detection 수행
- 매우 빠른 동작 시간, context의 손실이 없음
- 다른 domain에 적용했을 때, 다른 model들 보다 잘 작동함
4. Unified Detection
4.1. Object Detection Process

- Process
- input image에 \( S \times S \)의 grid를 생성
- 각 cell(grid의 각 칸)은 bounding box \( B \), 각 \( B \)에 대한 confidence, class에 대한 conditional probability 예측
- 각 \( B \)는 box의 중심좌표 \( (x, y) \), 높이, 너비, confidence 정보를 가짐
- \( confidence=\Pr{(Object)}\times IoU^{truth}_{pred} \)
- IoU와 confidence score를 사용하여 NMS를 수행해 최종 detection을 수행
- test 시, 특정 class에 대한 confidence score를 구하기 위해 아래 공식 이용
$$ \Pr{(Class_i|Object)}\times confidence=\Pr{(Class_i)}\times IoU^{truth}_{pred} $$
- 최종적으로 \( S \times S \times (B \times 5 + C) \) 크기의 tensor를 예측
- 논문에서는 Pascal VOC 데이터셋 실험을 위해 \( S=7 \), \( B=2 \), \( C=20 \)을 사용
 |
 |
4.2. Network Design
- GoogLeNet에서 영감을 받아 network를 설계하였음
- 24개의 convolution layer와 2개의 fully-connected layer로 구성
- layer의 중간중간에 max-pooling layer와 \( 1 \times 1 \)의 convolution layer를 사용하여 feature map의 차원을 축소시킴

4.3. Training
- 계산이 간편한 SSE(sum squared error)를 이용하여 error 계산을 수행
- 활성화 함수로 계산이 쉽고 빠른 Leaky ReLU 사용

- model의 전체 loss 계산 수식
$$\begin{align} &\lambda_{coord} \sum_{i=0}^{S^2}\sum_{j=0}^B \mathbb{1}_{ij}^{obj}[(x_i-\hat{x}_i)^2 + (y_i-\hat{y}_i)^2 ] \\&+ \lambda_{coord} \sum_{i=0}^{S^2}\sum_{j=0}^B \mathbb{1}_{ij}^{obj}[(\sqrt{w_i}-\sqrt{\hat{w}_i})^2 +(\sqrt{h_i}-\sqrt{\hat{h}_i})^2 ]\\ &+ \sum_{i=0}^{S^2}\sum_{j=0}^B \mathbb{1}_{ij}^{obj}(C_i - \hat{C}_i)^2 \\ & + \lambda_{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^B \mathbb{1}_{ij}^{noobj}(C_i - \hat{C}_i)^2 \\ &+ \sum_{i=0}^{S^2} \mathbb{1}_{i}^{obj}\sum_{c \in classes}(p_i(c) - \hat{p}_i(c))^2 \\ \end{align}$$
- loss 계산 수식에서, 각 요소의 의미
- \( \lambda_{coord} \) : object가 있는 경우에 중요도를 높게 부여(5의 값을 가짐)
- \( \lambda_{noobj} \) : object가 없는 경우에 중요도를 낮게 부여(0.5의 값을 가짐)
- \( \mathbb{1}_{ij}^{obj} \) : object가 있으면 1, 없으면 0의 값을 가짐
- \( \mathbb{1}_{ij}^{noobj} \) : object가 있으면 0, 없으면 1의 값을 가짐
- \( [(x_i-\hat{x}_i)^2 + (y_i-\hat{y}_i)^2 ] \) : \( B \)의 위치에 대한 SSE
- \( [(\sqrt{w_i}-\sqrt{\hat{w}_i})^2 +(\sqrt{h_i}-\sqrt{\hat{h}_i})^2 ] \) : \( B \)의 크기에 대한 SSE
- \( (C_i - \hat{C}_i)^2 \) : confidence에 대한 SSE
- \( (p_i(c) - \hat{p}_i(c))^2 \) : class probability에 대한 SSE
- 즉, \( B \)의 위치와 크기, 객체가 있는/없는 경우에 따른 중요도를 loss에 반영
- PASCAL VOC 2007, 2012 데이터셋에 대해 아래의 값을 이용하여 train, validation, test 수행
- epoch = 135
- batch size = 64
- momentum = 0.9
- decay = 0.0005
- learning rate
- 1~75 epoch = \( 10^{-2} \)
- 76~105 epoch = \( 10^{-3} \)
- 106~135 epoch = \( 10^{-4} \)
- overfitting을 예방하기 위해 dropout과 augmentation을 아래의 값을 이용하여 적용
- dropout rate = 0.5
- resize = ~20%
- exposure = ~10000%
- saturation = ~10000%
- HSV = 1.5
4.4. Inference
- 하나의 image에 \( S \times S \times B = 7 \times 7 \times 2 = 98 \)개의 \( B \)와, 각각의 \( B \)에 대한 class probability 예측
- NMS를 이용하여 중복되는 detection 방지를 통해 mAP를 2~3% 향상
4.5. Limitations
- 각 cell이 2개의 \( B \)를 가지며 하나의 class만을 예측하기 때문에, 여러 object들이 겹쳐져 있는 경우에 제대로 된 예측이 힘듬
- ex) 겹쳐져 있는 새 떼
- \( B \)에 대한 형태를 data를 통해 학습하기 때문에, 비정상적인 종횡비를 가진 \( B \)의 경우 예측이 힘듬
- ex) 일반적으로 생각하는 고무줄을 학습 한 뒤, 팽팽하게 늘어진 고무줄을 보는 경우
- 작은 크기의 \( B \)는 IoU에 큰 영향을 미치기 때문에, localization error가 높음
- ex) \( B \)의 작은 이동에도 IoU값이 크게 변함
5. Experiment
- 다른 real-time detection 시스템과 비교

- Fast R-CNN과 error에 대한 비교
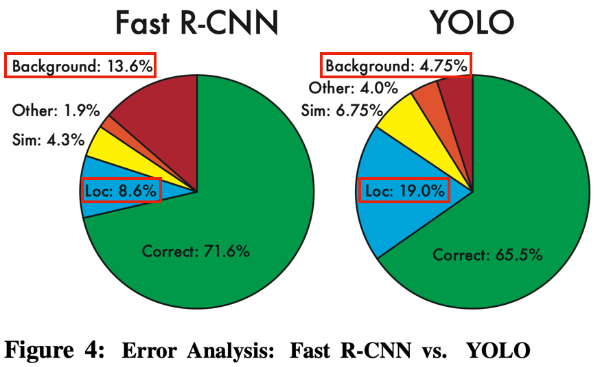
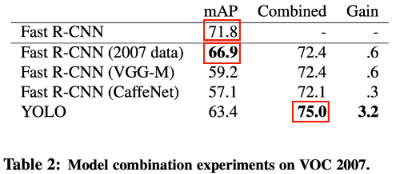
- Fast R-CNN에 YOLO를 비롯한 다른 model을 접목시켜 본 결과
- 당대의 SOTA 시스템과의 성능 비교

- 새로운 domain에 대한 test결과


6. Conclusion
- 모델 구성이 간단
- 다른 모델에 비해 빠른 처리속도와 높은 성능 덕분에 실시간 Detection에 적합
- Detection 성능에 직접적으로 대응하는 loss 계산식을 이용해 학습
- 이미지의 부분부분이 아닌 전체를 봄으로써, 새로운 domain에 대한 generalization능력 우수
논문 링크
https://arxiv.org/abs/1506.02640
728x90
반응형
'Paper Reading > Review' 카테고리의 다른 글
Contents
소중한 공감 감사합니다