Paper Reading/Review
[리뷰] MOTR: End-to-End Multiple-Object Tracking with TRansformer
- -
728x90
반응형
이번에는 ECCV 2022에 게재된 논문인 MOTR: End-to-End Multiple-Object Tracking with TRansformer를 읽고, 리뷰해보고자 합니다.
Index
1. Background
1.1. Tracking by Detection
1.2. Object Query
2. Abstract
3. Introduction
4. Related Work
5. Method
5.1. Revisiting Deformable DETR
5.2. Whole Architecture
5.3. Track Query
5.4. Continuous Query Passing
5.5. Query Interaction
5.5.1. Query Interaction Module
5.5.2. Temporal Aggregation Network
5.6. Overall Optimization
5.7. Difference between our track loss and detection loss in Deformable DETR
6. Experiment
7. Conclusion
1. Background
1.1. Tracking by Detection
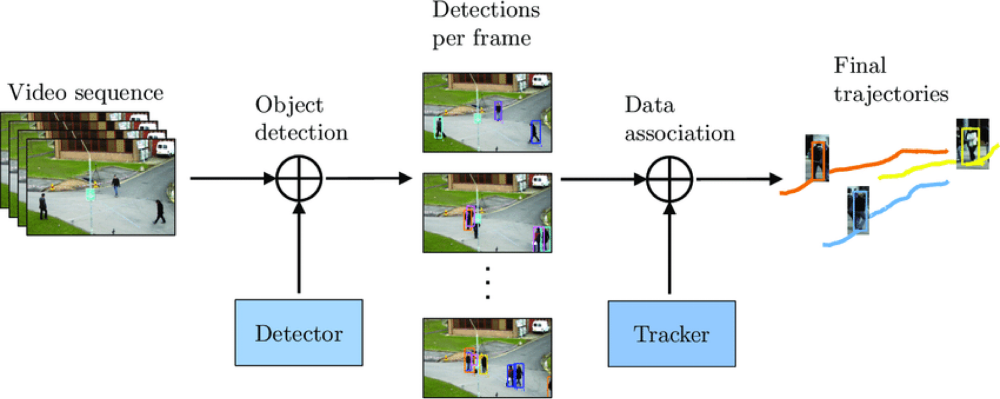
- IoU based 방식
- 공간적 유사도를 판정
- 각 frame에서 추출된 bounding box의 IoU값을 계산하여 연결
- 겹치는 영역이 일정 threshold 이상이면 같은 object라고 판단
- bounding box의 위치 계산을 돕는 Box regression(B)과 Classification(C) 두 개의 branch만을 사용
- Re-ID based 방식
- 형태적 유사도를 판정
- Re-ID(R)에 해당하는 하나의 branch를 추가하여 Re-ID feature embedding을 예측
- 연속된 두 frame에서 각 feature의 형태적인 유사도를 계산하여 높은 유사도를 가지는 쌍을 같은 object로 판단
- 이 요소들로 object를 추적하고, 실제 측정된 값들과 비교하며 상태를 업데이트

1.2. Object Query
- transformer기반의 object detection model인 DETR에서, transformer구조를 사용하기 위해 object query 라는 개념을 도입
- object query는 고정된 개수의 학습된 positional embedding 으로, 각 object class에 대해 이분적인 값을 가짐
- 특정 object에 대해서만 예측하도록 설계되어있지 않음
- tracking에 적합하지 않음

2. Abstract
- MOT의 핵심은 tracking중인 object에 대한 시간적 모델링이며, 이전까지의 방법은 occlusion과 같은 변칙적인 상황에 대해 모델링을 하기에 불충분
- 즉, 데이터에서 시간적 변화를 배울 수 있는 능력이 부족
- DETR을 기반으로 제작하여, 객체 쿼리와 비슷한 트랙 쿼리의 개념 도입
- 각 트랙 쿼리는 객체의 전체 트랙을 모델링하며, 항상 동일한 개체를 따름
- 각 프레임에서 트랙 쿼리 세트를 예측하며, 프레임별로 전송되고 업데이트
- 지속적인 쿼리 전달은 자연스럽게 시간적 연관성을 가짐
- NMS와 같은 작업을 제거 가능
3. Introduction
- 대부분의 MOT는 tracking by detection 방법 이용하며, IoU와 Re-ID 기반의 similarity를 이용
- occlusion, strong light, dark night, object deformation과 같은 경우에 Re-ID 기반 tracking은 적합하지 못함
- 명시적인 association 방법인 IoU나 Re-ID 기반과 같은 방법을 사용하지 않는 end-to-end 프레임워크, 트랙 쿼리, 연속 쿼리 전달 메커니즘을 제안
- 다중 frame 학습과 결합된 temporal aggregation network는 장거리 시간 관계를 모델링하는 데 도움이 되도록 추가로 제안
- 시간 정보 부족으로 인한 IDSW를 줄일 수 있음
4. Related Work
- transformer 기반 구조
- DETR, Deformable DETR, FPT, ViT 등
- 주로 MOT는 tracking-by-detection 방식을 따름
- SORT, DeepSORT, Tracktor, Track-RCNN, JDE, FairMOT 등
- DETR을 기반으로, TrackFormer와 몇 가지 유사점을 공유
5. Method
5.1. Revisiting Deformable DETR
- 객체 쿼리가 decoder를 통해 feature와 상호 작용하는 것을 보여주기 위해, Deformable DETR의 decoder를 재구성
- \( q^{k}=G_{ca}(G_{sa}(q^{k-1}), f) \), (\( q \in R^{c} \), \( f \in R^{c} \), \( k \in 1,\ \dots,\ K \))
- \( q \) : 객체 쿼리 세트, \( f \) : 인코더의 결과물인 feature map, \( C \) : feature의 차원, \( k \) : decoder 레이어의 수, \( q^{k} \) : \( k^{th} \) decoder layer의 output 쿼리, \( G_{sa} \) : DETR의 self-attention, \( G_{ca} \) : multi-scale deformable attention
- DETR의 높은 복잡성, 느린 수렴 문제를 해결하기 위해 transformer의 self-attention을 multi-scale deformable attention으로 대체
- \( q^{k}=G_{ca}(G_{sa}(q^{k-1}), f) \), (\( q \in R^{c} \), \( f \in R^{c} \), \( k \in 1,\ \dots,\ K \))
5.2. Whole Architecture
- 개략화 구조
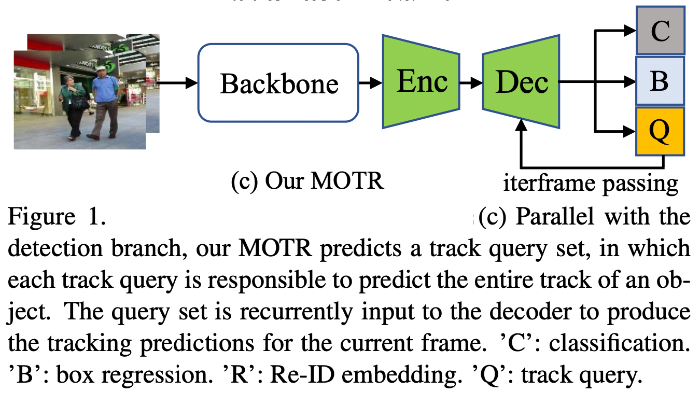
- 전체 구조

5.3. Track Query
- 트랙 쿼리를 모델링하기 위해 객체 쿼리를 확장
- 각 트랙 쿼리가 프레임에서 각각의 객체와 일치하면, 객체가 사라질 때까지는 각 객체의 전체 트랙을 매 frame마다 예측
- 새로 등장하는 객체를 위해, 빈 쿼리를 이용
- 쿼리의 순서 보존은 감독 학습으로 이루어짐
- data association이나 NMS의 과정을 제거할 수 있음

5.4. Continuous Query Passing

- 트랙 쿼리가 매칭된 object의 representation과 localization를 반복적으로 업데이트하기 위해 프레임별로 전달되고, 이를 통해 end-to-end를 달성
- object의 시간적 분산 모델링은 명시적인 association 대신 decoder의 multi-head attention에 의해 학습
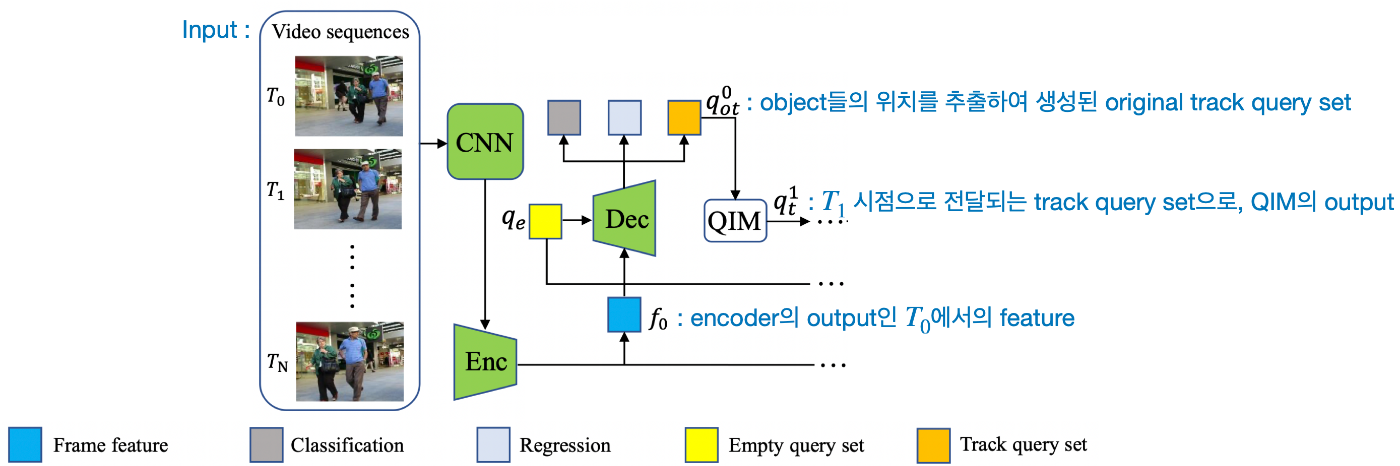
5.5. Query Interaction
- object 존재 유무를 판별하는 매커니즘과 temporal aggregation network를 포함
- object의 존재 유무 판별은 track score를 사용하여 예측
- TAN은 과거에 처리한 frame들에서 추적한 object에 대한 query를 모아 한번에 처리하는 query memory bank의 역할 수행
- 현재 frame의 track query는 multi-head attention을 통해 memory bank내의 각각의 query와 상호작용

5.5.1. Query Interaction Module
- Object Entrance
- GT와 비교를 통해 score를 함께 생성
- threshold값 \( \tau_{en} \)보다 score가 큰 경우에 새로 생성된 object가 맞다고 판단하여 해당 query만 남겨두고, 나머지 score가 작은 query들은 삭제
- Object Exit
- 현재의 frame만 보는 것이 아니라, 이전의 연속된 총 M개의 frame정보를 확인
- M개의 query score의 최댓값이 threshold값 \( \tau_{ce} \)보다 작은 경우에 사라진 object라고 판단하여 삭제

5.5.2. Temporal Aggregation Network
- tgt가 TAN의 multi-head attention 모듈에 input(value : \( V \), key : \( K \))으로 들어오면, attention weight를 생성
- 함께 input으로 들어온 \( \bar q^{i}_{c} \)와의 내적을 통해 계산
- 이후 \( q^{i}_{sa} \)가 feed forward neural network를 통과하고 다시 Normalized까지 거치고 나면 최종 output인 \( \hat{q}^{i}_{c} \)가 생성
- 최종 output은 현재 frame의 entrance query와 결합되어 다음 frame으로 전달

5.6. Overall Optimization
- 학습 시, train loss는 frame별로 계산되며, 전체 loss는 train set에 대한 모든 GT의 수에 의해 정규화된 모든 frame의 tracking loss의 합
- \( L_{ot}(Y,\hat{Y}) = \frac{\sum^{N}_{n=0}{(L_{t}(Y,\hat{Y}))}}{\sum^{N}_{n=0}{(V_{i})}} \)
- \( N \) : 비디오 시퀀스 길이, \( Y_{i} \)와 \( \hat{Y}_{i} \) : \( T_{i} \)frame의 예측과 GT, \( V_{i} \) : \( V^{i}_{t}+V^{i}_{e} \)로 \( T_{i} \) frame의 총 GT 수, \( V^{i}_{t} \)와 \( V^{i}_{e} \) : 추적된 object와 새로운 track의 수, \( L_{t} \) : Deformable DETR의 detection loss와 유사한 단일 frame의 tracking loss
- \( L_{t}(Y,\hat{Y}) = \lambda_{cls}L_{cls}+\lambda_{l_{1}}L_{l_{1}}+\lambda_{giou}L_{giou} \)
- \( L_{cls} \) : focal loss, \( L_{l_{1}} \) : L1 loss, \( L_{giou} \) : generalized된 IoU loss, 각 loss에 곱해진 \( \lambda_{*} \)는 각 요소의 가중치
- \( L_{ot}(Y,\hat{Y}) = \frac{\sum^{N}_{n=0}{(L_{t}(Y,\hat{Y}))}}{\sum^{N}_{n=0}{(V_{i})}} \)
5.7. Difference between our track loss and detection loss in Deformable DETR
- Deformable DETR의 tracking loss와 detection loss의 주요 차이점은 라벨 할당임
- detection loss의 경우, 라벨 할당은 모든 GT와 prediction간의 hungarian algorithm에 의해 결정
- tracking loss의 경우, 트랙 쿼리는 특정 object를 예측할 책임이 있기 때문에 GT와 쿼리가 추적하는 object에 의해 결정
- 빈 쿼리는, 예측의 GT 객체는 빈 쿼리의 prediction과 새로운 track의 GT 사이의 hungarian algorithm에 의해 결정
6. Experiment
- \( \tau_{en}=0.8 \), \( \tau_{ex}=0.6 \), \( M=5\)인 환경에서 실험
- MOT dataset에 대한 다른 tracker와의 성능 비교
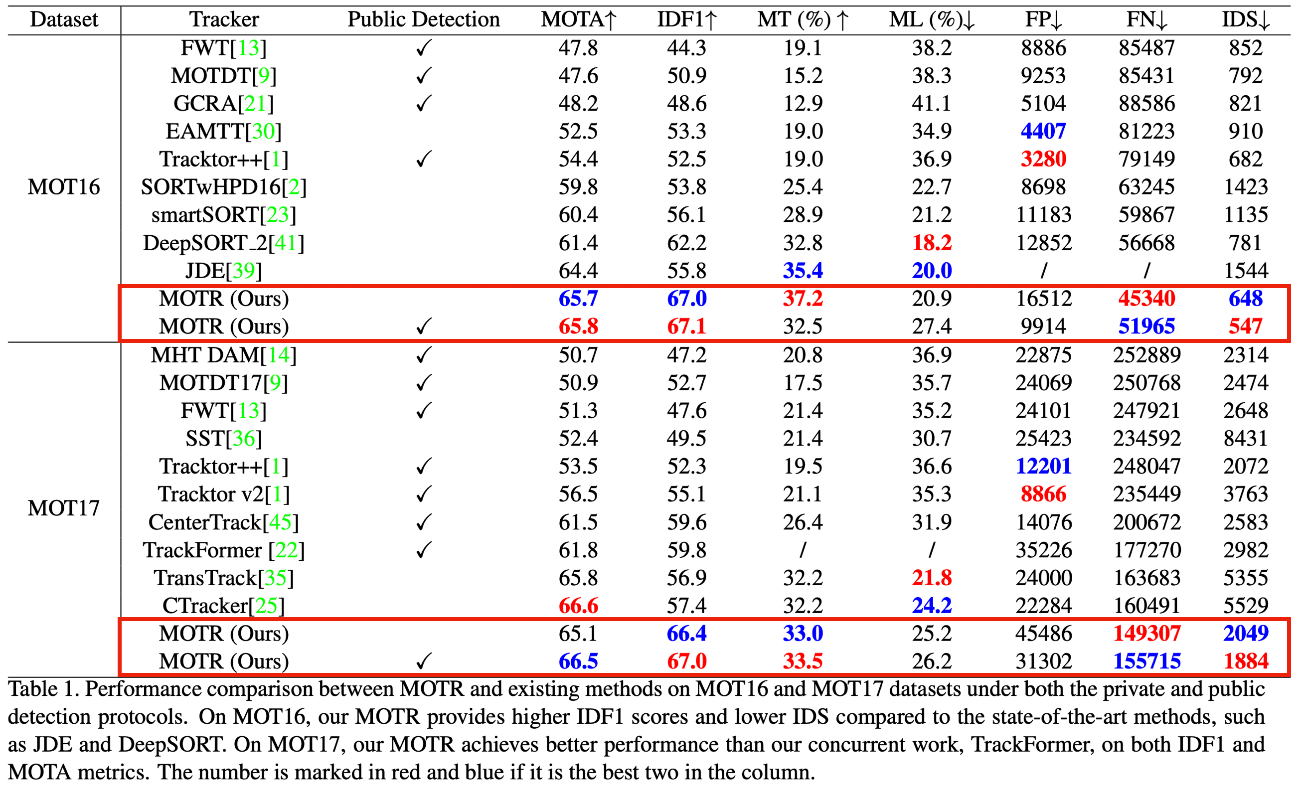
- M값의 변화에 따른 성능 변화


- TAN과 MFT의 적용에 따른 성능 변화

- 확률적으로 track query를 무작위로 지우는 것에 따른 성능 변화

- 확률적으로 FP인 track query를 무작위로 삽입하는 것에 따른 성능 변화

7. Conclusion
- Deformable DETR 기반의 IoU-matching이 요구되지 않는 트랙 쿼리의 반복적인 업데이트를 이용하는 end-to-end MOT 프레임워크 제안
- 트랙 쿼리 및 연속 쿼리 전달 개념 제안
- 시간적 관계를 강화하고 NMS의 필요성 제거
논문 링크
https://arxiv.org/abs/2105.03247
https://github.com/megvii-research/MOTR
참고 링크
728x90
반응형
'Paper Reading > Review' 카테고리의 다른 글
| [리뷰] BoT-SORT: Robust Associations Multi-Pedestrian Tracking (0) | 2023.02.27 |
|---|---|
| [리뷰] StrongSORT: Make DeepSORT Great Again (0) | 2023.02.24 |
| [리뷰] ByteTrack: Multi-Object Tracking by Associating Every Detection Box (0) | 2023.01.17 |
| [리뷰] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (0) | 2022.12.28 |
| [리뷰] Attention Mechanisms in Computer Vision: A Survey (1) | 2022.12.20 |
Contents
소중한 공감 감사합니다